
Computer Vision
中文翻译:计算机视觉
中文解释:使计算机从图像或视频中获取信息和理解内容的领域,包括目标检测、图像分类、语义分割等任务。

7 个月前
YOLO(You Only Look Once),这确实是目前计算机视觉领域最热门、应用最广泛的目标检测算法之一。 简单来说,如果把计算机看作一个学生,传统的检测算法像是让学生“拿着放大镜,一点点扫描图片里有什么”,而 YOLO 则是让学生“一眼扫过整张图,立刻说出图里有什么、在哪儿”。 这种“一眼识别”的特性,让 YOLO 在速度和准确性上取得了极佳的平衡。结合掌握的资料,这里为你详细拆解一下 YOLO 的核心原理、发展历程以及它在现实中的应用。 ? YOLO 的核心工作原理:像人眼一样“扫视” YOLO 的核心思想是将目标检测问题转化为一个回归问题。它不需要像旧算法(如 R-CNN)那样先猜区域再识别,而是通过一次神经网络计算,直接从图像像素回归出物体的位置和类别。 我们可以把它的工作流程想象成老师给班级分组: 网格划分(Grid Cells): 算法会将输入的图像划分为 S times S 个小格子(例如 7x7)。如果一个物体的中心点落在某个格子里,那个格子就“负责”检测这个物体。 边界框预测(Bounding Boxes): 每个格子会预测出几个边界框(例如 2 个),每个框包含 5 个参数:中心坐标 (x, y)、宽 w、高 h 以及一个置信度(表示框里确实有物体的概率)。 类别概率(Class Probabilities): 同时,每个格子还会预测这个框内物体属于各个类别的概率(比如是猫的概率 80%,是狗的概率 5%)。 非极大值抑制(NMS): 因为多个格子可能会检测到同一个物体,最后会通过 NMS 算法“去重”,保留得分最高的框,去掉重叠度高且得分低的框。 ? 从 V1 到 V8:YOLO 的进化之路 YOLO 算法自 2015 年诞生以来,经历了多次重大的架构升级。为了让你更直观地了解,这里整理了主要版本的演进逻辑: YOLOv1: 首次提出“单阶段检测”概念,将检测视为回归问题。 开创性工作,速度快,但小目标检测精度一般。 YOLOv2/v3: 引入 Anchor Boxes(先验框)和多尺度预测。 检测精度大幅提升,尤其是小物体。v3 成为经典里程碑。 YOLOv4: 集成了大量优化技巧(CSPDarknet, PANet, Mosaic数据增强)。 在保持速度的同时,精度达到了当时的顶尖水平。 YOLOv5: 基于 PyTorch 实现,工程化极佳。 极易上手,提供了从小到大的多种模型(s/m/l/x),部署方便,工业界主流。 YOLOv8: 最新主流版本,进一步优化了架构和损失函数。 性能更强,支持分类、检测、分割等多种任务,是目前的首选之一。 ? 为什么 YOLO 如此受欢迎? ⚡ 极快的速度: 由于只需要“看一次”,YOLO 可以轻松达到实时处理(如 45 FPS 甚至更高),非常适合处理视频流。 ? 全局视野: 它在预测时利用了整张图的上下文信息,因此在背景中误检(把背景当作物体)的概率比两阶段算法要低。 ?️ 强大的泛化能力: 它学习到的特征具有很好的通用性,迁移到其他数据集上通常也能取得不错的效果。 ? 实际应用场景 基于 YOLO 的这些特性,它在很多领域都有广泛的应用: ? 智慧安防: 实时监控画面中的人体检测、异常行为识别。 ? 自动驾驶: 识别道路上的车辆、行人、交通标志,为车辆决策提供依据。 ? 工业质检: 在生产线上快速识别产品缺陷、零件缺失或错位。 ? 医疗影像: 辅助医生识别 X 光片或 CT 图像中的病变区域(如肿瘤)。 ? 物流分拣: 识别包裹上的条形码或分类标签。 ? 对初学者的建议 如果想入门或使用 YOLO 进行图像识别: 新手入门: 推荐从 YOLOv5 或 YOLOv8 开始。它们的官方文档非常完善,代码(通常是 PyTorch 版本)易于理解,且社区支持丰富。 数据准备: 图像识别的效果很大程度上取决于数据。你需要准备标注好的数据集(通常标注工具会生成 .txt 或 .xml 文件,标明物体的类别和坐标)。 硬件要求: 虽然 YOLO 很快,但训练过程通常还是需要 GPU(如 NVIDIA 显卡)来加速。
1 年前
Covision Lab专注于计算机视觉和机器学习的公司,致力于将最先进的技术应用于工业领域的挑战,包括制造业、电子商务、印刷、农业和移动性等行业。
2 年前
语音视觉技术是一种结合了语音识别和计算机视觉的交叉学科技术,通过分析和理解人类语言以及视觉信息,实现人机交互和智能处理。
2 年前
AI 中的语音视觉技术是人工智能领域的重要组成部分。语音技术包括语音识别、语音合成、声纹识别等子领域。例如,语音识别技术能将人类语音信号转换成对应的文本或命令,如今已广泛应用于语音助手、自动驾驶、智能家居等领域。像苹果的 Siri 可以通过语音识别和语音合成技术,接收用户的语音指令,并用语音回复用户的请求,方便用户控制手机或其他智能设备。 视觉技术方面,计算机视觉是 AI 领域应用场景丰富、商业化价值较大的赛道。计算机视觉主要处理图像和视频等高维、密集数据,涉及图像处理、模式识别、计算机视觉、神经网络等多门学科。其应用涵盖了工业、安防、医疗、无人驾驶等众多领域。比如在安防领域,视觉 AI 技术可进行人群分析、逃犯追捕,通过城市中的大量摄像头对目标人群进行锁定与筛查,并实时告警,提升安防效率。 近年来,语音视觉技术不断取得突破和发展。国际数据公司(IDC)发布报告预测,未来人工智能领域将继续高歌猛进,语言、声音和视觉技术以及多模态解决方案将取得长足发展。在新的 AI 视觉浪潮兴起的背景下,产业的关注重心正从文本转向视觉,从单模态转向多模态。像旷视科技正从一家 AI 视觉公司,进化成一家多模态大模型公司,围绕“大模型+机器人”的发展方向,推动人工智能为实体产业创造更大价值。同时,随着技术的进步,语音视觉技术在教育等领域也成为重要的应用场景,为人们的生活和工作带来了诸多便利和创新。 AI 语音视觉技术的发展历程 AI 语音视觉技术的发展经历了多个阶段。早期,语音技术主要基于传统的音频信号处理方法,在语音压缩、麦克风阵列、回声消除等领域取得了一定成果。上世纪 90 年代,语音识别技术逐渐兴起,但其准确性受到诸多限制,如语音干扰、音频杂音、口音等因素的影响。 随着人工智能技术的引入,AI 语音技术应运而生。它将机器学习、神经网络等技术应用于语音识别,极大地提升了准确性,使人机互动更加自然简便。同时,视觉技术方面,计算机视觉从处理简单图像逐渐发展到处理复杂的视频数据,涉及多门学科,应用领域也不断扩展。 近年来,AI 语音视觉技术不断取得突破。例如,科大讯飞的产品在语音转写、批改作文等方面超越了人类水平,在国际英语合成大赛中表现出色。云鲸的清洁产品在制图导航和避障技术上有较大突破,实现了更高效的清洁效果。 未来,AI 语音视觉技术有望在准确性、智能化、多场景应用等方面持续发展,为人们的生活带来更多便利。 AI 语音视觉技术的最新应用案例 在当今社会,AI 语音视觉技术有着众多令人瞩目的应用案例。比如,科大讯飞董事长刘庆峰在世界人工智能大会上展示了其领先的语音翻译技术,能够实现大学六级口语水平的英语语音到语音机器翻译,且预计明年上半年达到专业八级水平。 云鲸的扫拖机器人和洗地机在智能清洁领域表现出色,拥有强大的吸力和创新的滚刷设计,解决了毛发缠绕问题,在制图导航和避障技术上也有显著突破。 港铁(深圳)4 号线深圳北站上线的多功能智能终端,具备 AI 视觉识别定位技术,支持 AR 实景与 VR 虚拟双重导航服务,还能提供智能 AI 语音问询等多项服务。 OpenAI 公布的“语音引擎”模型,仅需 15 秒音频样本就能生成与原始说话者相似的自然语音,应用于帮助失语者恢复声音、提供阅读帮助等方面。 这些案例充分展示了 AI 语音视觉技术在不同领域的创新应用和巨大潜力。 语音视觉技术在教育领域的应用挑战 语音视觉技术在教育领域的应用虽然带来了诸多便利,但也面临着一些挑战。 环境噪声干扰是一个重要问题。在教育环境中,如教室中的背景噪音、学生之间的交流声等,会对语音识别的准确性产生影响。这可能导致语音指令无法准确识别,影响教学效果。 方言和口音差异也给语音视觉技术的普适性带来挑战。不同地区的学生可能带有各自的方言和口音,这会增加语音识别的难度,导致识别错误或不准确。 此外,隐私保护也是不容忽视的问题。教育场景中产生的语音和视觉数据涉及学生的个人隐私,需要采取严格的保护措施,防止数据泄露和滥用。 为了应对这些挑战,需要不断优化语音识别算法,提高抗干扰能力和方言口音识别能力,同时建立健全的隐私保护机制。 多模态技术与语音视觉技术的融合前景 多模态技术与语音视觉技术的融合具有广阔的前景。在智能家居场景中,用户可以通过语音或手势控制设备,多模态技术能够结合语音和手势识别,实现更精确的控制,提升家居生活的智能化程度。 在自动驾驶领域,多模态学习可以利用视觉、音频和其他传感器数据,对交通场景进行全方位感知和理解,更准确地识别和预测道路上的障碍物、行人和交通信号,提高行驶的安全性和效率。 在增强现实(AR)和虚拟现实(VR)中,多模态技术通过结合视觉、音频和身体感知等多种输入方式,为用户提供更丰富和沉浸式的体验,使其能够更好地与虚拟环境进行交互。 在医疗领域,多模态技术可应用于疾病诊断和健康监测,通过结合医学影像与声音数据或其他生物传感器数据,提高医学影像的解读准确性,辅助医生进行疾病分析和诊断。 未来,随着技术的不断进步和数据资源的积累,多模态技术与语音视觉技术的融合将在更多领域实现创新和突破,为人们的生活和工作带来更大的价值。 AI 语音视觉技术的关键突破点 AI 语音视觉技术的关键突破点主要包括以下几个方面。 在多模态智能方面,实现对不同类型数据的全面和准确分析理解,推动技术在人脸识别、机器翻译、视频理解等领域的广泛应用。未来需注重数据融合集成,优化算法,提高模型泛化和鲁棒性。 复杂内容的创作是另一个突破点,应用于广告、游戏、文学等领域。未来需注重模型优化和个性化服务,结合多种技术提高对复杂数据的理解分析能力。 情感智能的发展也至关重要,能够识别和理解人类情感状态并针对性交流回复。未来需注重情感认知和响应机制研究应用,结合相关技术提升效果。 此外,语音视觉技术在提高准确性、降低杂音、适应方言口音等方面的突破,以及在跨模态检索、图像描述生成、视觉问答系统等方面的创新应用,都将推动 AI 语音视觉技术不断发展进步。 综上所述,AI 语音视觉技术在多个领域展现出强大的潜力和应用价值。其发展历程充满了创新和突破,最新的应用案例不断涌现,在教育领域面临挑战的同时也有着广阔的发展空间。多模态技术与语音视觉技术的融合将开启更多可能,而关键突破点的攻克将推动这一技术迈向更高的台阶,为人类社会带来更多的便利和进步。 来源:豆包AI
2 年前
语音视觉技术在教育、医疗、交通、娱乐等多个领域的应用将越来越广泛,为人们的生活和工作带来更多的便利和创新。
2 年前
谭铁牛,中国科学院院士、英国皇家工程院外籍院士、发展中国家科学院院士、巴西科学院外籍院士,模式识别与计算机视觉专家。

9 天前
西门子Xcelerator开放式数字商业平台作为正式发布生态合作伙伴"繁星计划",旨在发挥平台网络效应,与生态伙伴共享知识与技术资源,共创面向客户的解决方案,共赢数字化与低碳化新机遇。
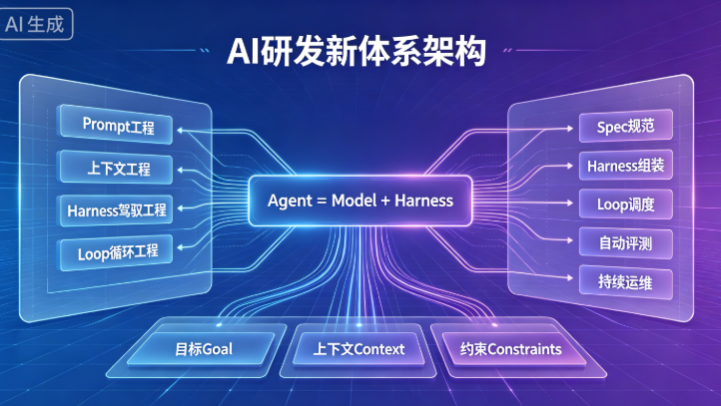
14 天前
AI 研发已从单点 Prompt 优化迭代至Harness 工程底座 + Loop 自治闭环 + SDD 标准化规范的三位一体体系,通过重构人机协作模式,解决大模型落地不稳定、难规模化的痛点,实现企业级 AI 从原型试用走向工程化、自动化、体系化落地。










