
1 天前
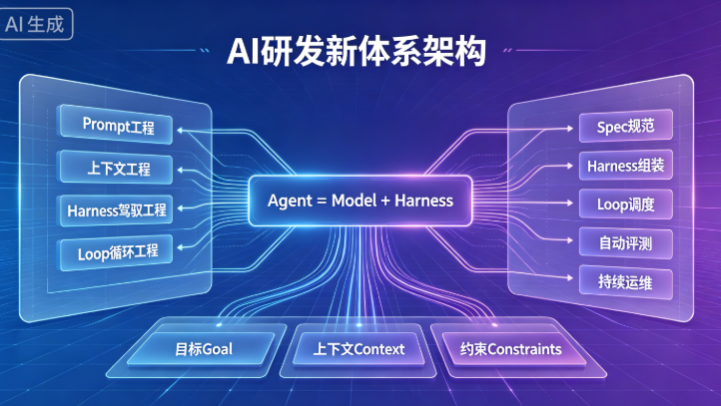
Harness 是包裹大模型、管控智能体执行流程、施加硬性约束与外部能力的整套运行控制系统。

11 天前
西门子Xcelerator开放式数字商业平台作为正式发布生态合作伙伴"繁星计划",旨在发挥平台网络效应,与生态伙伴共享知识与技术资源,共创面向客户的解决方案,共赢数字化与低碳化新机遇。
17 天前
AI 研发已从单点 Prompt 优化迭代至Harness 工程底座 + Loop 自治闭环 + SDD 标准化规范的三位一体体系,通过重构人机协作模式,解决大模型落地不稳定、难规模化的痛点,实现企业级 AI 从原型试用走向工程化、自动化、体系化落地。

21 天前
WorkBuddy有望拿下国内独立桌面自动化办公智能体细分第一。但受企业协同生态、移动端能力等短板限制,无法成为全域企业及全球办公AI赛道第一名,将与钉钉悟空、WPS AI形成差异化竞争格局。





















































































































































































































































































