
Gemma 2 不仅有了更轻量级「Gemma 2 2B」版本,还构建一个安全内容分类器模型「ShieldGemma」和一个模型可解释性工具「Gemma Scope」。

Gemma 2 2B 具有内置安全改进功能,实现了性能与效率的强大平衡;ShieldGemma 基于 Gemma 2 构建,用于过滤 AI 模型的输入和输出,确保用户安全;Gemma Scope 提供对模型内部工作原理的无与伦比的洞察力。
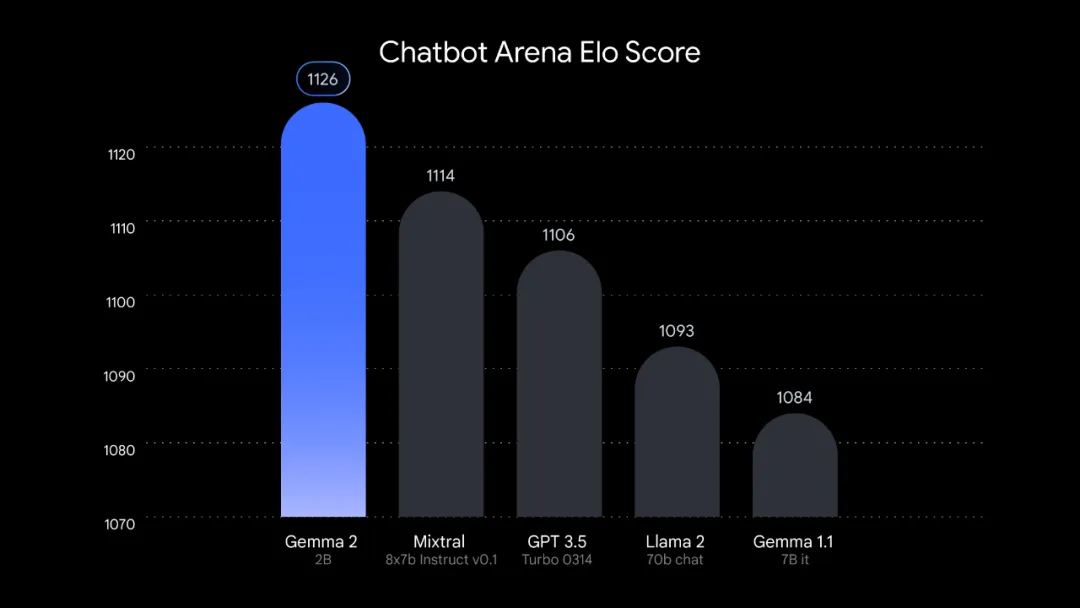
其中,Gemma 2 2B 无疑是「最耀眼的仔」,它在大模型竞技场 LMSYS Chatbot Arena 中的结果令人眼前一亮:仅凭 20 亿参数就跑出了 1130 分,这一数值要高于 GPT-3.5-Turbo(0613)和 Mixtral-8x7b。
这也意味着,Gemma 2 2B 将成为端侧模型的最佳选择。
Gemma 2 2B 越级超越 GPT-3.5 Turbo
Gemma 2 家族新增 Gemma 2 2B 模型,备受大家期待。谷歌使用先进的 TPU v5e 硬件在庞大的 2 万亿个 token 上训练而成。
这个轻量级模型是从更大的模型中蒸馏而来,产生了非常好的结果。由于其占用空间小,特别适合设备应用程序,可能会对移动 AI 和边缘计算产生重大影响。
事实上,谷歌的 Gemma 2 2B 模型在 Chatbot Arena Elo Score 排名中胜过大型 AI 聊天机器人,展示了小型、更高效的语言模型的潜力。下图表显示了 Gemma 2 2B 与 GPT-3.5 和 Llama 2 等知名模型相比的卓越性能,挑战了「模型越大越好」的观念。
Gemma 2 2B 提供了:
性能卓越:在同等规模下提供同类最佳性能,超越同类其他开源模型;部署灵活且经济高效:可在各种硬件上高效运行,从边缘设备和笔记本电脑到使用云部署如 Vertex AI 和 Google Kubernetes Engine (GKE) 。为了进一步提高速度,该模型使用了 NVIDIA TensorRT-LLM 库进行优化,并可作为 NVIDIA NIM 使用。此外,Gemma 2 2B 可与 Keras、JAX、Hugging Face、NVIDIA NeMo、Ollama、Gemma.cpp 以及即将推出的 MediaPipe 无缝集成,以简化开发;开源且易于访问:可用于研究和商业应用,由于它足够小,甚至可以在 Google Colab 的 T4 GPU 免费层上运行,使实验和开发比以往更加简单。
用户可以从 Kaggle、Hugging Face、Vertex AI Model Garden 下载模型权重。用户还可以在 Google AI Studio 中试用其功能。
Gemma 2 2B 的出现挑战了人工智能开发领域的主流观点,即模型越大,性能自然就越好。Gemma 2 2B 的成功表明,复杂的训练技术、高效的架构和高质量的数据集可以弥补原始参数数量的不足。这一突破可能对该领域产生深远的影响,有可能将焦点从争夺越来越大的模型转移到改进更小、更高效的模型。
Gemma 2 2B 的开发也凸显了模型压缩和蒸馏技术日益增长的重要性。通过有效地将较大模型中的知识提炼成较小的模型,研究人员可以在不牺牲性能的情况下创建更易于访问的 AI 工具。这种方法不仅降低了计算要求,还解决了训练和运行大型 AI 模型对环境影响的担忧。
资讯来源:机器之心

6 个月前
这正是当前 AI 视频生成领域最前沿的突破方向。你提出的这个问题,本质上是在问如何让 AI 从“画皮”进阶到“画骨”——即不仅画面好看,运动逻辑也要符合现实世界的物理法则。 结合最新的技术进展(如 2025 年的相关研究),要让 AI 生成符合真实规律的视频,我们可以通过以下几种“高级语言描述法”来与模型沟通: 1. 使用“力提示”技术:像导演一样指挥物理力 ? 这是谷歌 DeepMind 等团队提出的一种非常直观的方法。你不需要懂复杂的物理公式,只需要在提示词中描述“力”的存在。 描述力的方向与强度: 你可以直接告诉 AI 视频中存在某种力。例如,不只是写“旗帜飘动”,而是写“旗帜在强风中剧烈飘动”或“气球被轻轻向上吹起”。 区分全局力与局部力: 全局力(风、重力): 影响整个画面。例如:“Global wind force blowing from left to right”(从左到右的全局风力)。 局部力(碰撞、推力): 影响特定点。例如:“A ball rolling after being kicked”(球被踢后滚动)。 效果: AI 模型(如 CogVideoX 结合特定模块)能理解这些力的矢量场,从而生成符合动力学的运动,比如轻的物体被吹得更远,重的物体移动缓慢。 2. 调用“思维链”与物理常识:让 LLM 当质检员 ? 有时候直接描述很难精准,我们可以借助大型语言模型(LLM)作为“中间人”来审核物理逻辑。这种方法(如匹兹堡大学的 PhyT2V)利用 LLM 的推理能力。 分步描述(Chain-of-Thought): 你可以在提示词中要求 AI “思考过程”。例如,不只是生成“水倒入杯子”,而是引导它:“首先,水从壶嘴流出,形成抛物线;然后,水撞击杯底,产生涟漪;最后,水位上升,流速减慢。” 明确物理规则: 在提示词中直接嵌入物理常识。例如:“根据重力加速度,球下落的速度应该越来越快”或“流体具有粘性,流动时会有拉丝效果”。 回溯修正: 如果第一版视频不符合物理规律(比如球浮在空中),你可以通过反馈指令让系统进行“回溯推理”,识别出视频与物理规则的语义不匹配,并自动修正提示词重新生成。 3. 参数化控制:像物理老师一样给定数值 ? 如果你需要极其精确的物理运动(例如做科学实验模拟或电影特效),可以使用类似普渡大学 NewtonGen 框架的思路,直接给定物理参数。 设定初始状态: 在语言描述中包含具体的物理量。 位置与速度: “一个小球从坐标 (0, 10) 以初速度 5m/s 水平抛出”。 角度与旋转: “一个陀螺以角速度 10rad/s 旋转”。 质量与材质: “一个轻质的泡沫块”与“一个沉重的铁球”在相同力作用下的反应是不同的。 指定运动类型: 明确指出是“匀速直线运动”、“抛物线运动”还是“圆周运动”。AI 会根据这些语义,调用内置的“神经物理引擎”来计算轨迹,确保视频中的物体运动轨迹符合牛顿定律。 4. 结合物理引擎的混合描述:虚实结合 ? 更高级的方法是让语言描述直接驱动物理模拟器(如 Blender, Genesis),然后将结果渲染成视频。 描述物理属性: 在提示词中指定物体的密度、弹性系数、摩擦力等。 事件驱动描述: 描述物体间的相互作用。例如:“一个刚性的小球撞击一个柔软的布料,布料发生形变并包裹住小球”。 通用物理引擎: 像 Genesis 这样的新模型,允许你用自然语言描述复杂的物理场景(如“一滴水滑落”),它能直接生成符合流体动力学的模拟数据,而不仅仅是看起来像视频的图像帧。 ? 总结:如何写出“物理级”提示词? 为了更直观地掌握这种描述方式,这里总结了一个对比表: 一句话总结: 要用语言描述物理运动,关键在于将“视觉结果”转化为“物理过程”。多用描述力(风、推力)、属性(重力、粘性)、参数(速度、角度)的词汇,甚至直接告诉 AI 要遵循某种物理规律,这样生成的视频才会有真实的“重量感”和“真实感”。

6 个月前
利用大语言模型(LLM)构建虚拟的“世界模型”(World Models),以此作为 KI 智能体(AI Agents)积累经验和训练的场所。 核心概念:让 LLM 成为 AI 的“模拟练习场” 目前,开发能在现实世界执行复杂任务的 AI 智能体(如机器人、自动化软件助手)面临一个巨大挑战:获取实际操作经验的成本极高且充满风险。 如果让机器人在物理世界中通过“试错”来学习,不仅效率低下,还可能造成硬件损毁。 研究人员提出的新思路是:利用已经掌握了海量人类知识的大语言模型(LLM),由它们通过文字或代码生成一个模拟的“世界模型”。 1. 什么是“世界模型”? 世界模型是一种模拟器,它能预测特定行为可能产生的结果。 传统方式: 需要开发者手动编写复杂的代码来定义物理法则和环境规则。 LLM 驱动方式: 预训练的大模型(如 GPT-4 或 Claude)已经具备了关于世界运行逻辑的知识(例如:知道“推倒杯子水会洒”)。研究人员可以利用 LLM 自动生成这些模拟环境的逻辑。 2. 研究的具体内容 来自上海交通大学、微软研究院、普林斯顿大学和爱丁堡大学的国际研究团队对此进行了深入研究。他们测试了 LLM 在不同环境下充当模拟器的能力: 家庭模拟(Household Simulations): 模拟洗碗、整理房间等日常任务。 电子商务网站(E-Commerce): 模拟购物行为、库存管理等逻辑。 3. 关键发现: 强结构化环境表现更佳: 在规则清晰、逻辑严密的场景(如简单的文本游戏或特定流程)中,LLM 驱动的模拟效果非常好。 开放世界的局限性: 对于像社交媒体或复杂的购物网站这类高度开放的环境,LLM 仍需要更多的训练数据和更大的模型参数才能实现高质量的模拟。 真实观察的修正: 实验显示,如果在 LLM 模拟器中加入少量来自现实世界的真实观察数据,模拟的质量会显著提升。 对 AI 行业的意义 加速 AI 智能体进化: 这种方法让 AI 智能体可以在几秒钟内完成数千次的虚拟实验,极大加快了学习速度。 降低训练门槛: 开发者不再需要搭建昂贵的物理实验室,只需要调用 LLM 接口就能创建一个“训练场”。 2026 年的趋势: 这预示着 2026 年及以后,“自主智能体”将成为 AI 发展的核心,而这种“基于模拟的学习”将是通往通用人工智能(AGI)的关键一步。 总结 该研究证明,LLM 不仅仅是聊天机器人,它们可以演变成复杂的“数字世界创造者”。在这个虚拟世界里,新一代的 AI 智能体可以安全、低成本地反复磨练技能,最终再将学到的能力应用到现实生活和工作中。 ( 根据海外媒体编译 )

8 个月前
LoRA(Low-Rank Adaptation)是一种对大模型进行“轻量级微调”的技术。

8 个月前
Gemini 3 标志着AI模型从“增量优化”向“范式转变”的重大跃进。

9 个月前
DeepSeek OCR 介绍 DeepSeek OCR 是由中国 AI 公司 DeepSeek AI 于 2025 年 10 月 20 日发布的开源视觉语言模型(VLM),旨在探索“光学上下文压缩”(Contexts Optical Compression)的创新范式。它不是传统的 OCR(光学字符识别)工具,而是将视觉编码视为文本信息的压缩层,帮助大型语言模型(LLM)更高效地处理长文档、图像和多模态数据。 该模型的灵感来源于“一图胜千言”的理念,通过将文本转化为视觉表示,实现显著的令牌(token)减少,同时保持高准确性。 核心创新与架构 DeepSeek OCR 的核心思想是将文本作为图像处理,从而实现高效压缩: 视觉-文本压缩:传统 LLM 处理 1000 字文档可能需要数千个文本令牌,而 DeepSeek OCR 通过视觉编码器将图像压缩为更少的视觉令牌(可减少 7-20 倍),然后解码回文本。测试显示,它能保留 97% 的原始信息。 双阶段架构: DeepEncoder:视觉编码器,负责图像处理,包括文档、图表、化学分子和简单几何图形。它基于先进的视觉模型(如 Vary、GOT-OCR2.0 和 PaddleOCR 的灵感),高效提取特征。 DeepSeek-3B-MoE:解码器,使用混合专家模型(MoE,激活参数仅 5.7 亿),生成文本输出。整个模型大小约为 6.6 GB,运行速度快、内存占用低。 多功能扩展:除了基本 OCR,它支持解析图表(生成 Markdown 表格和图表)、化学公式、几何图形,甚至自然图像。深解析模式(Deep Parsing Mode)特别适用于金融图表等结构化数据。 该模型在 OmniDocBench 等基准测试中达到了端到端模型的 SOTA(最先进)性能,优于 MinerU 2.0 和 GOT-OCR2.0 等更重的模型,同时视觉令牌使用最少。 它还支持 vLLM(虚拟 LLM 推理引擎),便于批量处理。 优势与应用场景 效率提升:减少计算成本,适合处理长上下文(如聊天历史或长文档)。例如,将旧对话“低分辨率”存储为图像,模拟人类记忆衰减机制。 实用性:在 OCR 之外,它能处理复杂视觉任务,如从图像中提取结构化数据,而非简单文本复制。 开源与易用:模型托管在 Hugging Face(deepseek-ai/DeepSeek-OCR),支持 PyTorch 和 CUDA。GitHub 仓库提供完整代码和示例。 局限性:作为实验性模型,对简单矢量图形解析仍有挑战;输出有时可能出现幻觉(如中文符号混入英文响应)。 如何使用(快速入门) 安装依赖:克隆 GitHub 仓库(git clone https://github.com/deepseek-ai/DeepSeek-OCR.git),安装 Transformers 和 vLLM。 Python 示例(使用 Hugging Face): from transformers import AutoModel, AutoTokenizer from PIL import Image import torch model_name = 'deepseek-ai/DeepSeek-OCR' tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) model = AutoModel.from_pretrained(model_name, trust_remote_code=True, torch_dtype=torch.bfloat16).cuda().eval() # 加载图像 image = Image.open("your_image.png").convert("RGB") # 提示(prompt) prompt = "<image>\nFree OCR." # 或其他任务提示,如 "<image>\nParse chart." inputs = tokenizer(prompt, return_tensors="pt").to(model.device) inputs = image # 添加图像 with torch.no_grad(): outputs = model.generate(**inputs, max_new_tokens=512) print(tokenizer.decode(outputs, skip_special_tokens=True)) 这将从图像中提取并输出文本。 DeepSeek OCR 代表了 OCR 从“文本提取”向“多模态压缩”转型的趋势,对于 AI 研究者和开发者来说,是一个值得关注的开源工具。

11 个月前
T5:Text-to-Text Transfer Transformer

1 年前
? OpenAI即将发布GPT-4.1,多模态能力再升级! 据多家科技媒体报道,OpenAI计划于下周(2025年4月中旬)推出GPT-4.1,作为GPT-4o的升级版本,进一步强化多模态推理能力,并推出轻量级mini和nano版本。 ? 关键升级点 更强的多模态处理 GPT-4.1将优化对文本、音频、图像的实时处理能力,提升跨模态交互的流畅度。 相比GPT-4o,新模型在复杂推理任务(如视频理解、语音合成等)上表现更优。 轻量化版本(mini & nano) GPT-4.1 mini 和 nano 将面向不同应用场景,降低计算资源需求,适合移动端或嵌入式设备。 配套新模型(o3 & o4 mini) OpenAI还将推出o3推理模型(满血版)和o4 mini,优化特定任务性能。 部分代码已在ChatGPT网页端被发现,表明发布临近。 ⏳ 发布时间与不确定性 原定下周发布,但OpenAI CEO Sam Altman 曾预警可能因算力限制调整计划。 同期,ChatGPT已升级长期记忆功能,可回顾用户历史对话,提供个性化服务(Plus/Pro用户已开放)。 ? 行业影响 谷歌(Gemini AI)和微软(Copilot)近期也强化了AI记忆功能,竞争加剧。 GPT-4.1可能进一步巩固OpenAI在多模态AI领域的领先地位,推动商业应用(如智能客服、内容创作等)。 ? 总结:GPT-4.1的发布标志着OpenAI在多模态AI上的又一次突破,但具体性能提升和落地效果仍需观察。我们将持续关注官方更新! (综合自腾讯新闻、The Verge、搜狐等)

1 年前
谷歌大模型与人脑语言处理机制研究由谷歌研究院与普林斯顿大学、纽约大学等合作开展。3 月上旬,谷歌的研究成果表明大模型竟意外对应人脑语言处理机制。他们将真实对话中的人脑活动与语音到文本 LLM 的内部嵌入进行比较,发现两者在线性相关关系上表现显著,如语言理解顺序(语音到词义)、生成顺序(计划、发音、听到自己声音)以及上下文预测单词等方面都有惊人的一致性 研究方法:将真实对话中的人脑活动与语音到文本LLM的内部嵌入进行比较。使用皮层电图记录参与者在开放式真实对话时语音生成和理解过程中的神经信号,同时从Whisper中提取低级声学、中级语音和上下文单词嵌入,开发编码模型将这些嵌入词线性映射到大脑活动上。 具体发现 语言理解与生成顺序:在语言理解过程中,首先是语音嵌入预测沿颞上回(STG)的语音区域的皮层活动,几百毫秒后,语言嵌入预测布罗卡区(位于额下回;IFG)的皮层活动。在语言生成过程中,顺序则相反,先由语言嵌入预测布罗卡区的皮层活动,几百毫秒后,语音嵌入预测运动皮层(MC)的神经活动,最后,在说话者发音后,语音嵌入预测STG听觉区域的神经活动。这反映了神经处理的顺序,即先在语言区计划说什么,然后在运动区决定如何发音,最后在感知语音区监测说了什么。 神经活动与嵌入的关系:对于听到或说出的每个单词,从语音到文本模型中提取语音嵌入和基于单词的语言嵌入,通过估计线性变换,可以根据这些嵌入预测每次对话中每个单词的大脑神经信号。全脑分析的定量结果显示,在语音生成和语音理解过程中,不同脑区的神经活动与语音嵌入和语言嵌入的峰值存在特定的先后顺序和对应关系。 “软层次”概念:尽管大模型在并行层中处理单词,人类大脑以串行方式处理它们,但反映了类似的统计规律。大脑中较低级别的声学处理和较高级别的语义处理部分重叠,即存在“软层次”概念。例如,像IFG这样的语言区域不仅处理单词级别的语义和句法信息,也捕捉较低级别的听觉特征;而像STG这样的低阶语音区域在优先处理声学和音素的同时,也能捕捉单词级别的信息。 以往相关研究成果 2022年发表在《自然神经科学》上的论文显示,听者大脑的语言区域会尝试在下一个单词说出之前对其进行预测,且在单词发音前对预测的信心会改变在单词发音后的惊讶程度(预测误差),证明了自回归语言模型与人脑共有的起始前预测、起始后惊讶和基于嵌入的上下文表征等基本计算原理。 发表在《自然通讯》的论文发现,大模型的嵌入空间几何图形所捕捉到的自然语言中单词之间的关系,与大脑在语言区诱导的表征(即大脑嵌入)的几何图形一致。 后续研究还发现,虽然跨层非线性变换在LLMs和人脑语言区中相似,但实现方式不同。Transformer架构可同时处理成百上千个单词,而人脑语言区似乎是按顺序、逐字、循环和时间来分析语言。 总之,该研究表明,语音到文本模型嵌入为理解自然对话过程中语言处理的神经基础提供了一个连贯的框架,尽管大模型与人脑在底层神经回路架构上存在明显不同,但在处理自然语言时有着一些相似的计算原则。









