
MinerU,作为一款全能、开源的文档与网页数据提取工具,致力于简化您的数据处理流程。它不仅能将混合了图片、表格、公式等在内的多模态PDF文档精准转化为清晰、易于分析的Markdown格式;还能从包含广告等各种干扰信息的网页中快速解析、抽取正式内容;同时支持epub、mobi、docx等多种格式批量转化为Markdown……它既是一个能让你轻松愉快完成复杂版面数据提取、文档转化的“高手”!更能凭借批量、快速、准确的性能,成为你的AI语料准备“得力助手”。接下来,让我们用2分钟时间,深入了解一下它的功能和特色。
它既是一个能让你轻松愉快完成复杂版面数据提取、文档转化的“高手”!更能凭借批量、快速、准确的性能,成为你的AI语料准备“得力助手”。接下来,让我们用2分钟时间,深入了解一下它的功能和特色。

快速识别与转换MinerU中的Magic-PDF能够快速识别PDF版面元素,自动删除页眉、页脚、脚注等非正文内容,保留原文档的结构和格式,包括标题、段落、列表等,准确提取图片、表格和公式等多模态内容,并根据顺序,将文档转化为清晰、通顺、易读的Markdown格式。

公式再多的文档也不用担心,效果远超其他开源工具。另外乱码PDF、扫描版PDF等也能自动识别并转换……还有很多惊喜能力,等你发现。

Web网页信息轻松提取常见的文章、论坛、音乐、视频等类型网页信息提取,MinerU中的Magic-Doc可以轻松剔出广告等干扰信息,快速搞定正文、评论、歌词、视频文字详情等关键内容转化。


7 个月前
AI图片生成集成指南:从API到SDK的完整实现路径 在腾讯EdgeOne Pages模版详情页面点击“Deploy”按钮,填写必要的API密钥,点击“开始部署”——短短几分钟内,一个完整的AI图片生成应用就这样上线了。 随着人工智能技术的快速发展,AI图片生成功能已成为现代应用中不可或缺的一部分。无论是内容创作、产品设计还是营销素材制作,AI图片生成技术都能提供高效、创新的解决方案。 对于开发者而言,如何将这项能力快速、安全地集成到自己的应用中,成为了一个值得深入探讨的课题。 01 理解两种集成路径 原生API调用和AI SDK封装调用是当前将AI图片生成能力集成到应用中的两种主要技术路径,每种路径都有其独特的优势和应用场景。 原生API调用提供了精细控制和高度灵活性,开发者可以直接与底层API交互,定制化程度高。AI SDK则通过统一接口简化了开发流程,实现了多厂商模型的轻松切换。 以EdgeOne Pages为例,这两种集成方式都有对应的模版:ai-image-generator-starter用于原生接口调用,而ai-sdk-image-generator-starter则适用于AI SDK封装调用。 在开始集成之前,开发者需要根据自身需求选择合适的技术路径。对于追求控制和定制化的项目,原生API调用是更好的选择;而对于希望快速上线并支持多种模型的项目,AI SDK封装调用则更为合适。 02 快速入门:环境准备与部署 要实现AI图片生成功能,首先需要申请API Key。主流AI图片生成提供商的API Key获取地址包括: Hugging Face:huggingface.co/settings/tokens OpenAI:platform.openai.com/api-keys Replicate:replicate.com/account/api-tokens Fal:fal.ai/dashboard/keys Nebius:nebius.com/console 部署过程简单直观。以ai-sdk-image-generator-starter模版为例,在模版详情页面点击“Deploy”按钮,系统将跳转到EdgeOne Pages控制台。 在部署界面,开发者需要配置环境变量,这些配置项对应不同AI图片生成服务的API Key。不同模版会呈现不同的配置项列表,但必须确保至少有一个API Key配置正确且可用。 完成配置后点击“start deployment”按钮,项目就会开始自动部署。部署成功后,GitHub帐户下会生成一个与模版相同的项目,开发者可以通过git clone命令将其下载到本地进行进一步的开发和定制。 03 原生API调用详解 原生API调用方式让开发者能够精细控制每一个请求细节。在这一模式下,图片生成的基本流程是:前端发送生图参数到边缘函数,边缘函数调用AI模型API,最后将生成的图片返回给前端显示。 在前端部分,用户需要配置可用的AI模型列表。以src/pages/index.tsx文件中的核心代码为例: const res = await fetch("/v1/generate", { method: "POST", headers: { "Content-Type": "application/json", }, body: JSON.stringify({ image: `${prompt} (${modelInfo.name} style)`, platform: platform.id, model: modelInfo.value || selectedModel, }), }); 边缘函数的处理逻辑位于functions/v1/generate/index.js文件中。函数首先接收前端传递的参数,然后检查对应平台的环境变量是否配置正确。 const validateToken = (platform) => { const tokens = { nebius: env.NEBIUS_TOKEN, huggingface: env.HF_TOKEN, replicate: env.REPLICATE_TOKEN, openai: env.OPENAI_API_KEY, fal: env.FAL_KEY, }; if (!tokens) { throw new Error( `${platform} API token is not configured. Please check your environment variables.` ); } }; 这种通过env访问环境变量的方式,有效防止了API密钥在代码中明文暴露,提高了应用的安全性。敏感信息存储在环境变量中,而非硬编码在源代码里。 环境变量检查完成后,函数会直接请求对应平台的图片生成模型API。以HuggingFace为例,其标准API请求核心代码如下: const response = await PROVIDERS.fetch(url, { headers: { Authorization: `Bearer ${token}`, "Content-Type": "application/json", }, method: "POST", body: JSON.stringify(data), }); EdgeOne Pages的AI图片生成模版已经支持了多种主流模型,包括HuggingFace、OpenAI、Replicate、Fal、Nebius等。生成图片后,函数将结果返回给前端,模版项目内已经内置了图片显示的完整逻辑。 04 AI SDK封装调用解析 与原生API调用方式相比,AI SDK封装调用通过统一接口简化了开发流程。它允许开发者使用相同的代码结构调用不同厂商的AI图片模型,显著提高了开发效率和多模型切换的便利性。 在AI SDK方式下,前端通过/api/generate接口发送请求: const response = await fetch(apiUrl, { method: "POST", headers: { "Content-Type": "application/json", }, body: JSON.stringify({ prompt, model, size, }), }); 这里需要注意的是,size参数需要提前设置,因为不同的模型支持的尺寸列表可能不一致。 例如,DALL-E 3支持“1024x1024”、“1024x1792”、“1792x1024”等尺寸,而Stable Diffusion可能支持“512x512”、“768x768”等不同规格。 EdgeOne Pages的AI SDK图片生成模版已经梳理了AI SDK支持模型对应的尺寸列表,相关配置位于components/modelSizeMapping.ts文件中。开发者可以直接使用这些预配置的尺寸映射,无需手动处理不同模型的尺寸兼容性问题。 AI SDK同样避免了密钥泄漏风险。函数在调用AI图片模型时,使用AI SDK暴露的experimental_generateImage对象来统一生成图片内容,密钥的获取由experimental_generateImage在内部自动处理。 const imageResult = await experimental_generateImage({ model: imageModel, prompt: prompt, size: size, // Use frontend-provided size }); 调用experimental_generateImage后,只需要读取函数返回的标准格式内容即可: const imageUrl = `data:image/png;base64,${imageResult.image.base64}`; return new Response( JSON.stringify({ images: [ { url: imageUrl, base64: imageResult.image.base64, }, ], }) ); 05 本地调试与持续集成 开发者在下载项目到本地后,可能需要进行本地开发、调试或预览。为了简化本地环境配置,EdgeOne提供了专门的CLI工具。 使用EdgeOne CLI需要先安装并登录,具体步骤可以参考EdgeOne CLI的文档介绍。在安装和登录后,开发者可以在本地项目下执行edgeone pages link命令,将项目与EdgeOne Pages控制台的项目进行关联。 执行该命令后,系统会提示输入EdgeOne Pages的项目名,即上文部署的模版项目的项目名称。输入项目名后,EdgeOne Pages控制台的环境变量会自动同步到本地。 关联成功后,本地项目根目录下会生成.env文件,包含所有已配置的环境变量列表。关联后,可以执行edgeone pages dev命令来进行本地部署,部署后可以在localhost:8088进行访问。 对于代码的自定义修改,开发者可以直接通过git提交项目到GitHub。EdgeOne Pages会检测GitHub的提交记录并自动进行重新部署,实现真正的持续集成与持续部署。 部署完成后,控制台会显示部署状态和预览界面,开发者可以立即验证功能是否正常工作。 AI图片生成集成后的应用界面,简洁直观。模板提供了开箱即用的用户界面,用户可以直接输入提示词、选择模型和调整参数,生成结果会即时显示在右侧区域。 在本地测试过程中,如果对生成效果或性能有特定要求,开发者可以灵活切换不同的AI模型提供商。不同的模型在风格表现、细节处理等方面各有特色,有些专注于写实风格,有些擅长艺术创作,实际测试是找到最适合项目的关键一步。 ( 文章来源:Tencent Cloud )

1 年前
我们在开发网站的时候,往往有想克隆别人网站的想法。那么在技术上怎么才能实现呢? ⚠️ 重要提示 确认目标网站的版权和合法性:如果你没有目标网站的授权,直接克隆并使用可能会侵犯版权或违反法律。 如果只是想模仿其功能或界面,建议自行开发类似的网站,而不是直接复制。 如果你拥有授权,可以使用以下方法进行克隆。 ? 方法 1:使用 HTTrack 下载整个网站 HTTrack 是一个网站克隆工具,可用于离线浏览: 下载安装 HTTrack(Windows/macOS/Linux 都支持)。 创建新项目 并输入目标网站 URL地址。 启动克隆,HTTrack 会下载 HTML、CSS、JS、图片等资源。 本地查看和编辑,然后上传到自己的服务器。 缺点: 只能克隆静态页面(HTML、CSS、JS),无法克隆后端功能(如 API、数据库、登录系统等)。 如果目标网站有反爬虫策略,可能无法完整下载。 ? 方法 2:手动分析 & 重新开发 如果你想复制网站的功能,而不仅仅是外观,建议进行以下操作: 1. 分析网站前端 使用 Chrome 开发者工具(F12) 查看 HTML 结构、CSS 样式和 JavaScript 逻辑。 使用 Postman 或浏览器 Network 面板 分析 API 接口调用方式(如果适用)。 复制或编写类似的 HTML/CSS/JS 代码,实现前端界面。 2. 分析网站后端 如果网站有 API 接口、数据库等后端功能,需要: 观察 API 调用(GET/POST 请求)以了解数据交互方式。 搭建类似的后端(Node.js、Python、PHP、Go 等),并使用数据库(MySQL、MongoDB 等)。 如果网站使用的是 OpenAI API,你可以在 申请 API Key,然后在你的项目中集成 ChatGPT 或 DALL·E 相关功能。 3. 部署你的网站 本地开发:使用 HTML + CSS + JavaScript + 后端框架(如 Flask、Express、Django)。 云端部署:选择服务器(AWS、阿里云、Vultr、腾讯云等)并部署网站。 ? 方法 3:使用 Web Scraping(仅用于数据获取) 如果你只想获取网页上的文本数据,可以使用 Python + BeautifulSoup / Selenium 进行爬取: import requests from bs4 import BeautifulSoup url = "http://openai.cha-tai.cn/" response = requests.get(url) soup = BeautifulSoup(response.text, 'html.parser') # 提取页面文本 text = soup.get_text() print(text) 注意: 如果网站有反爬虫机制,可能需要使用 Selenium 或 Scrapy 进行爬取。 只能获取静态数据,无法克隆网站的功能。 ? 结论 如果你只是想获取网站的内容,HTTrack 或 Web Scraping 可能够用。 但如果你想克隆网站的功能,建议分析前端和后端结构,并自行开发。

1 年前
一款适用于任何网站的自动数据提取工具
1 年前
有几款网站数据分析AI工具值得推荐: Webutler.AI Webutler.AI是一款适用于任何网站的自动数据提取工具。它基于人工智能来分析出网页最合适的数据,并允许将其下载并保存到Excel。该工具不需要特定于网站的脚本,而是通过对HTML结构来检测出关联数据并选择最合适的列表。常用场景包括收集产品价格和评论、分析社交媒体网站等。 MonkeyLearn MonkeyLearn是另一个无编码平台,它使用人工智能数据分析功能来帮助用户可视化和重新排列数据。它提供了一系列预训练的机器学习模型,可用于情感分析、主题分类、命名实体识别等。 MAXQDA MAXQDA是一款定性数据分析软件,提供了广泛的分析方法工具,如扎根理论、定性内容分析、话语分析、混合方法等。它使定性数据分析比以往更快、更容易,并提供了直观易学的界面。 总的来说,这些AI工具可以帮助网站所有者自动执行内容分析和数据采集任务,节省大量时间和精力。通过使用先进的算法和机器学习模型,它们能够快速准确地提取和分析网站内容,为网站优化和内容策略提供有价值的洞见。 推荐官:Perplexity.ai

1 年前
使用Wix, illa Cloud和Mixo等AI工具创建无代码网站。

9 天前
西门子Xcelerator开放式数字商业平台作为正式发布生态合作伙伴"繁星计划",旨在发挥平台网络效应,与生态伙伴共享知识与技术资源,共创面向客户的解决方案,共赢数字化与低碳化新机遇。
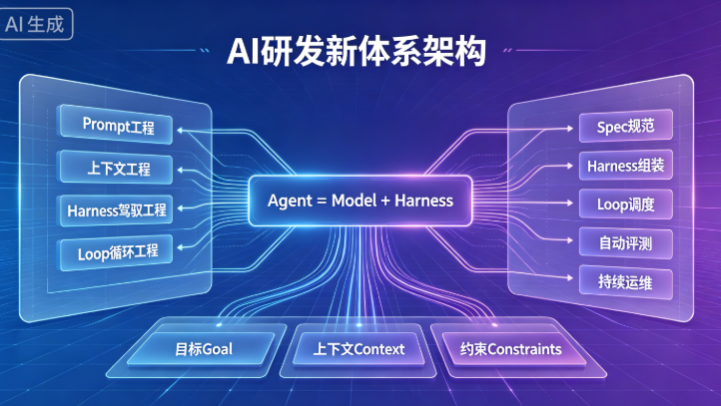
14 天前
AI 研发已从单点 Prompt 优化迭代至Harness 工程底座 + Loop 自治闭环 + SDD 标准化规范的三位一体体系,通过重构人机协作模式,解决大模型落地不稳定、难规模化的痛点,实现企业级 AI 从原型试用走向工程化、自动化、体系化落地。

19 天前
WorkBuddy有望拿下国内独立桌面自动化办公智能体细分第一。但受企业协同生态、移动端能力等短板限制,无法成为全域企业及全球办公AI赛道第一名,将与钉钉悟空、WPS AI形成差异化竞争格局。


















