
随着深度学习,特别是超大规模预训练模型技术的发展,模型训练和推理所消耗的能源日益增长,这带来了更多的碳排放问题,对于全球气候可能造成不良影响。为了解决这一问题,研究者们开始探索研发更为绿色的AI算法及其相关技术。
1.绿色AI指的是在不增加,甚至降低计算成本的前提下,研发性能更为强大的AI模型的技术手段。
2.实现GreenAI主要有两个方面的手段,一是设定评价模型能效的方法;二是在模型架构、训练、推理、数据利用等方面进行研究。
绿色AI指的是在不增加,甚至降低计算成本的前提下,研发性能更为强大的AI模型的技术手段。[1] 绿色AI的概念最早由艾伦人工智能研究院等机构的研究者在2020年提出。
提出绿色AI概念的目的在于呼吁AI研究者重视人工智能带来的环境和可持续发展问题。据[2]统计,2018-2019年的国际顶会中,很多研究者关注AI的准确率而非效率。
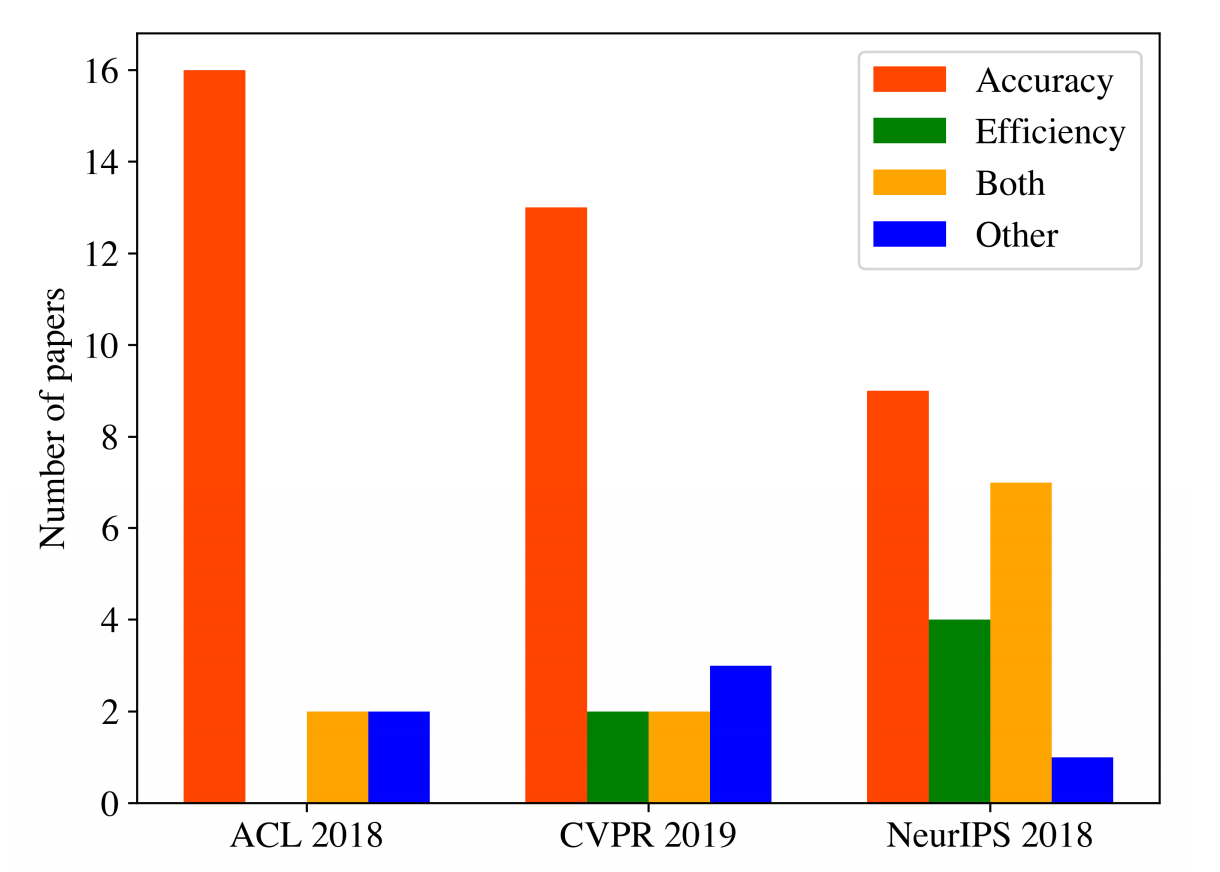
图注:顶会中研究者关注准确率、效率和二者兼有的比例 [2]
相对于绿色AI概念的是红色AI,指的是不计算力代价提升模型性能的技术和模型。[1] 与红色AI不同,绿色AI鼓励研究者尽可能减少模型训练和推理所消耗的算力资源。
2020年的绿色AI论文中,研究者认为实现绿色AI的首要工作是确定评价AI能耗的方法。[2] 在评价模型的效率的指标方面,包括:
(1)碳排放量
(2)电力消耗
(3)实时收敛时间
(4)参数规模
(5)浮点运算量(即达到预期效果所消耗的算力)

图注:计算红色AI的公式[3]
此外,有开源社区开发者提出了绿色AI标准,推动研究者上传评测结果,推动建立统一的能效评价体系。[4]

在[1]中,研究者认为应当在模型架构、训练方法、推理方法和数据使用等方面进行改进。主要包括:
(1)紧凑的模型架构:在更小规模的模型上实现更高性能;
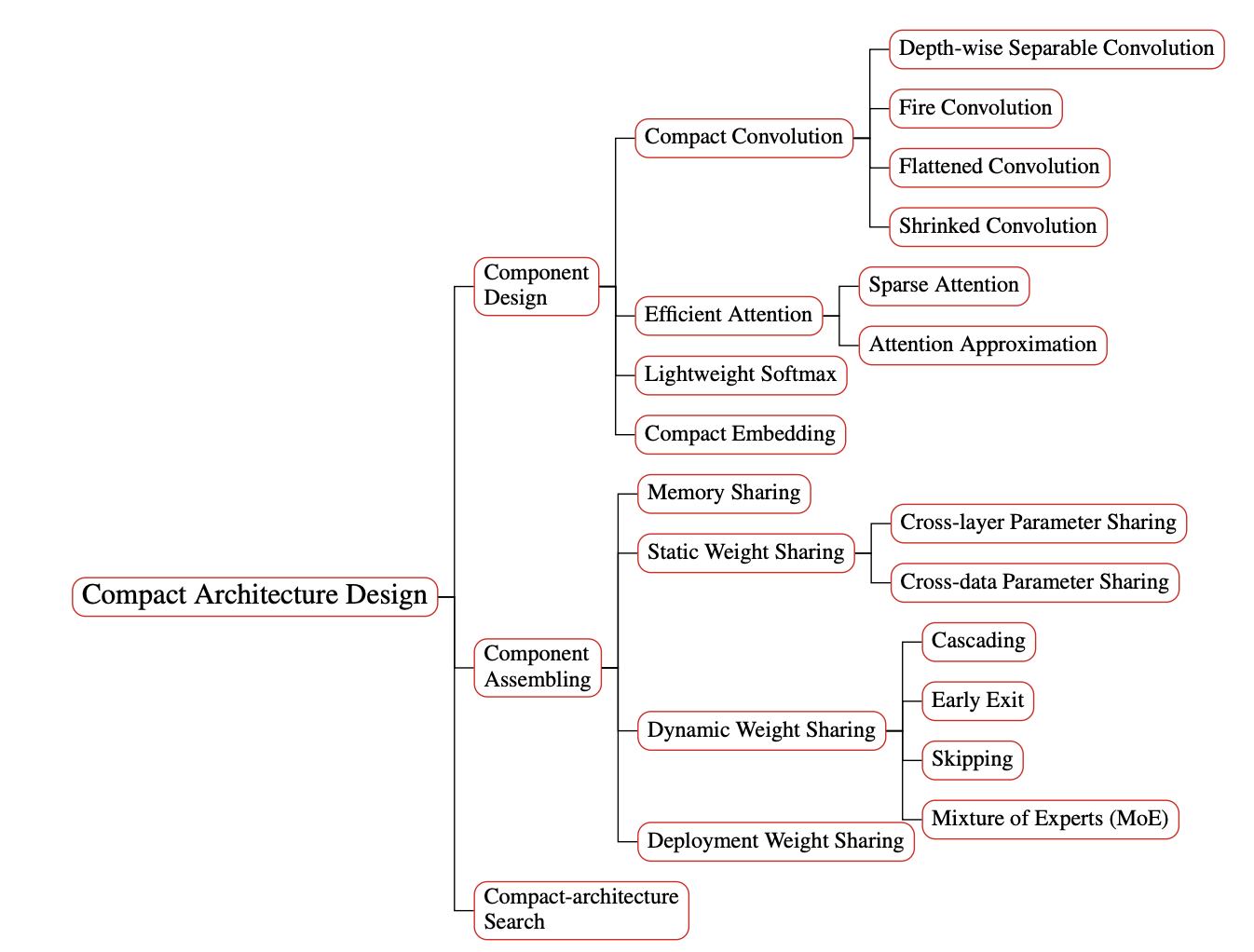
(2)高效的训练策略:在初始化、正则化、渐进式训练、高效自动机器学习(AutoML)等方面进行技术改进;
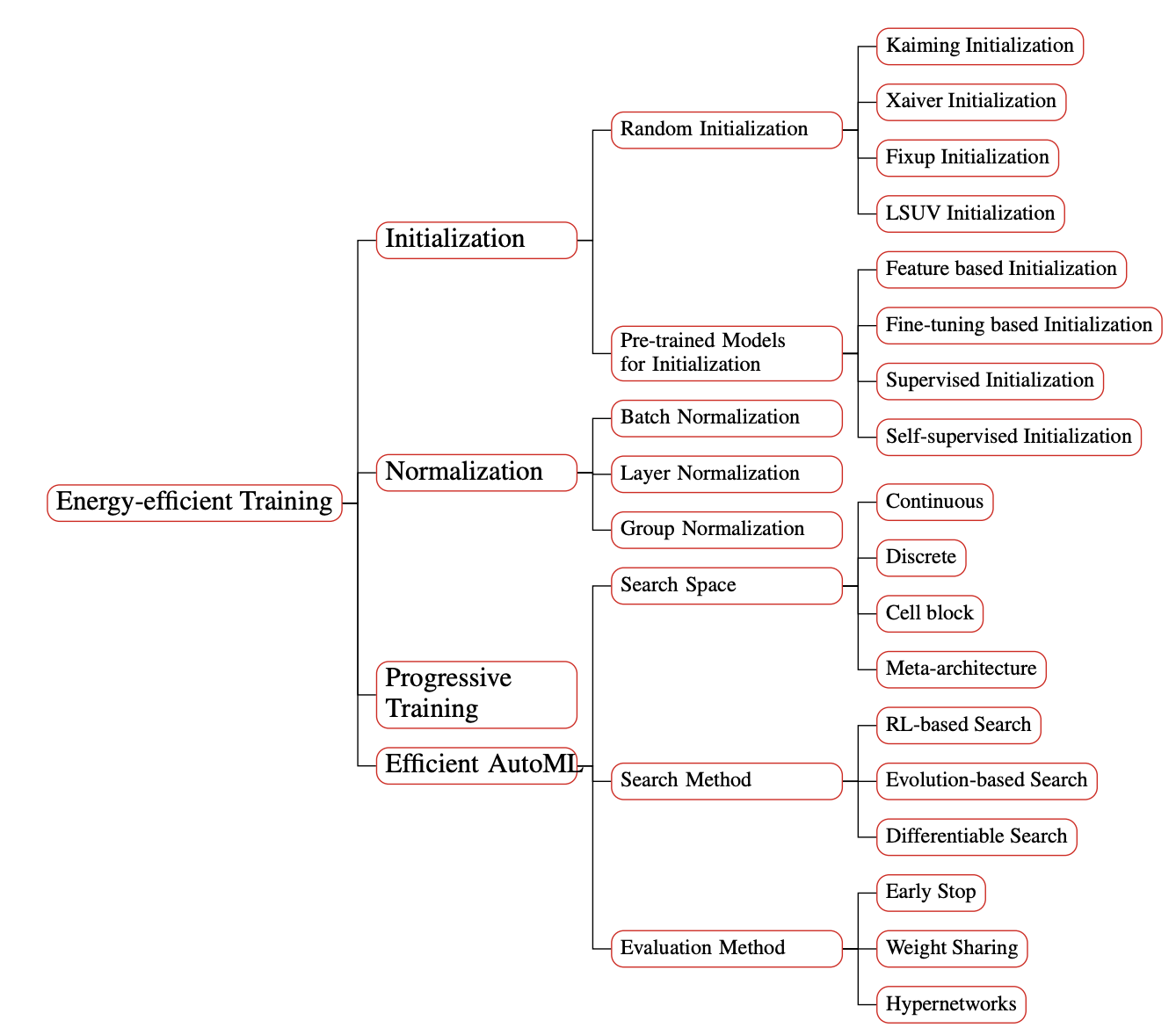
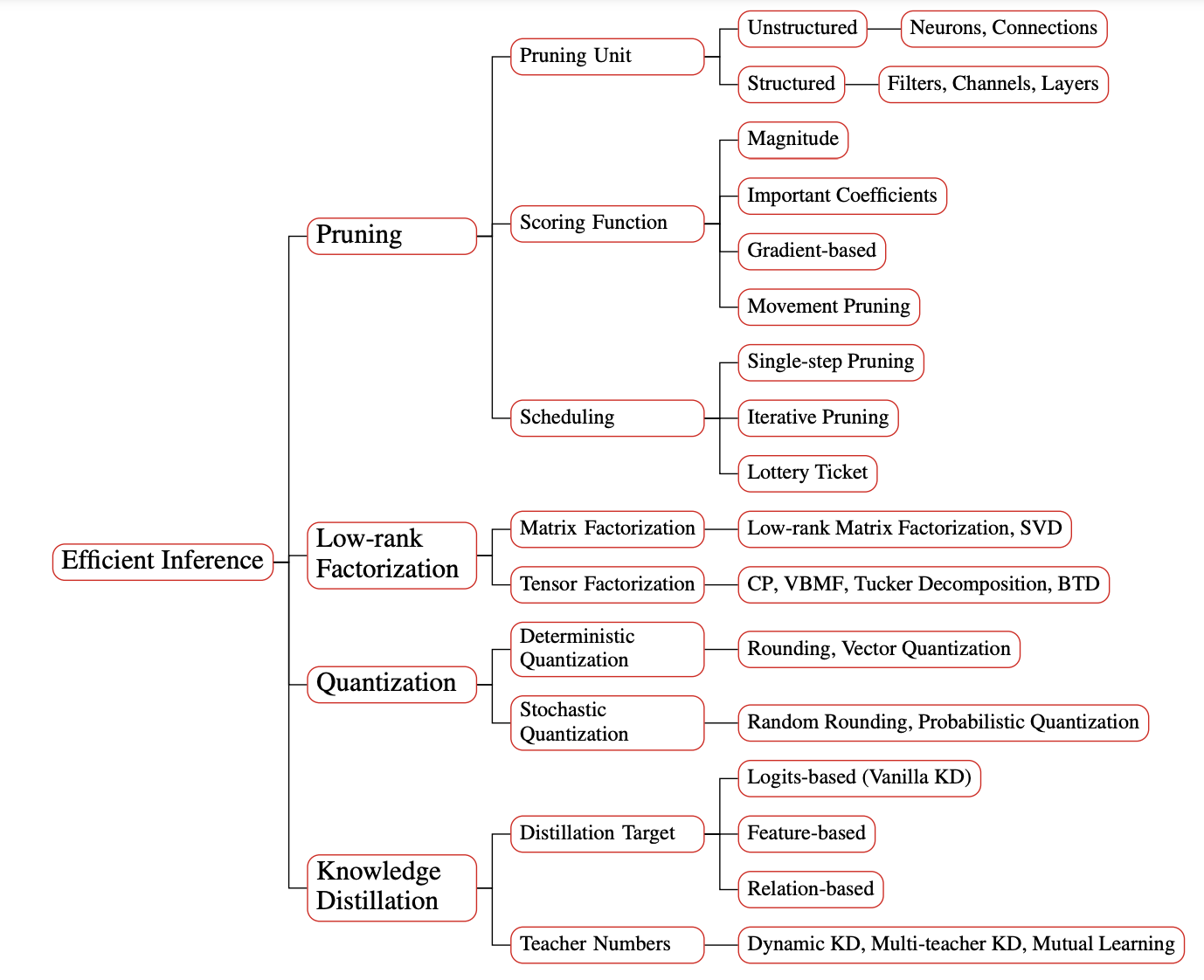
(3)高效推理策略:包括模型剪枝、蒸馏、低阶因式分解、数量化等;
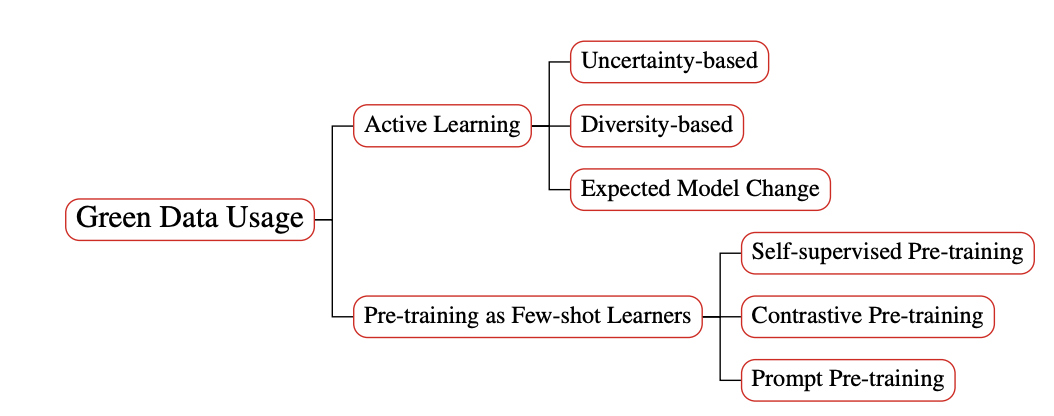
(4)高效数据利用:包括主动学习和小样本学习等。
[1] Xu, Jingjing, et al. "A Survey on Green Deep Learning." arXiv preprint arXiv:2111.05193 (2021).
[2] Schwartz, Roy, et al. "Green ai." Communications of the ACM 63.12 (2020): 54-63.
[3] Green AI:https://cacm.acm.org/magazines/2020/12/248800-green-ai/fulltext
[4] Green Artificial Intelligence Standard:https://github.com/daviddao/green-ai
文章来源:智源社区AI FrontPage

1 年前
阿西洛马人工智能原则(Asilomar AI Principles)是一套旨在确保人工智能(AI)技术安全、伦理和有益发展的指导原则。该原则于2017年1月在美国加利福尼亚州阿西洛马举行的“Beneficial AI”会议上提出,由“生命未来研究所”(Future of Life Institute)牵头制定,得到了包括斯蒂芬·霍金、埃隆·马斯克等在内的众多AI领域专家和学者的支持。 原则概述 阿西洛马人工智能原则共包含23条,分为三大类:科研问题、伦理和价值、更长期的问题。以下是各类别的核心内容: 1. 科研问题(Research Issues) 研究目标:AI研究应致力于创造有益于人类的智能,而非不受控制的智能。 研究经费:AI投资应部分用于研究如何确保其有益使用,包括计算机科学、经济学、法律、伦理等领域的问题。 科学与政策的联系:AI研究者与政策制定者之间应保持建设性交流。 科研文化:应培养合作、信任与透明的科研文化,避免因竞争而降低安全标准。 2. 伦理和价值(Ethics and Values) 安全性:AI系统应在整个生命周期内保持安全可靠,并在可行的情况下接受验证。 故障透明性:若AI系统造成损害,应能确定其原因。 责任:AI设计者和建造者应对其使用、误用及行为产生的道德影响负责。 价值归属:高度自主的AI系统应确保其目标与人类价值观一致。 个人隐私:人们应有权访问、管理和控制其生成的数据。 共同繁荣:AI创造的经济繁荣应惠及全人类。 3. 更长期的问题(Longer-term Issues) 能力警惕:应避免对未来AI能力上限的过高假设。 风险:AI系统可能带来的灾难性或存亡风险,需有针对性地减轻。 递归的自我提升:能够自我升级或复制的AI系统需受严格的安全控制。 公共利益:超级智能的开发应服务于广泛认可的伦理观念,而非单一国家或组织的利益。 原则的意义与影响 阿西洛马人工智能原则旨在为AI技术的发展提供伦理框架,确保其符合人类利益并避免潜在风险。这些原则不仅得到了学术界的广泛支持,也在政策制定和行业实践中产生了深远影响。 争议与挑战 尽管原则提出了明确的指导方向,但在实际应用中仍面临诸多挑战。例如,如何确保AI系统的价值归属与人类价值观一致,以及如何在全球范围内协调AI技术的监管等问题。 总结 阿西洛马人工智能原则为AI技术的发展提供了重要的伦理和安全指导,但其成功实施仍需全球范围内的合作与努力。如需了解更多细节,可参考相关文献或访问生命未来研究所的官方网站。

8 天前
西门子Xcelerator开放式数字商业平台作为正式发布生态合作伙伴"繁星计划",旨在发挥平台网络效应,与生态伙伴共享知识与技术资源,共创面向客户的解决方案,共赢数字化与低碳化新机遇。
14 天前
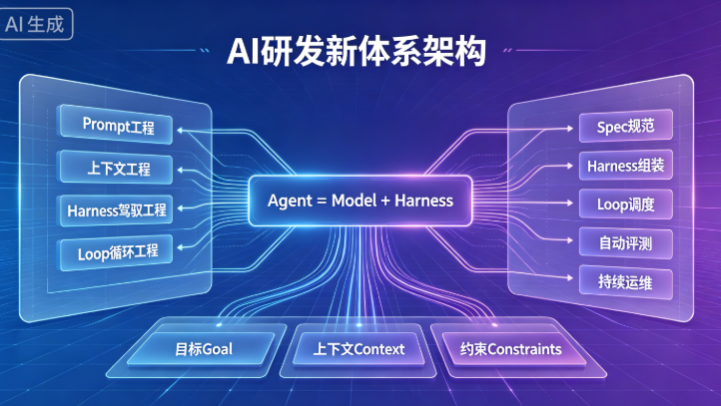
AI 研发已从单点 Prompt 优化迭代至Harness 工程底座 + Loop 自治闭环 + SDD 标准化规范的三位一体体系,通过重构人机协作模式,解决大模型落地不稳定、难规模化的痛点,实现企业级 AI 从原型试用走向工程化、自动化、体系化落地。

19 天前
WorkBuddy有望拿下国内独立桌面自动化办公智能体细分第一。但受企业协同生态、移动端能力等短板限制,无法成为全域企业及全球办公AI赛道第一名,将与钉钉悟空、WPS AI形成差异化竞争格局。

26 天前
OpenClaw工具与生态完整生命周期判断 本文尝试分短期、中期、长期三段,结合项目现状、风险、护城河客观测算OpenClaw这款智能体工具或者相似工具的发展趋势。 一、短期生命力(1~3年,2026–2029):完全安全、高速增长,是黄金运营窗口期 支撑理由 赛道刚需独一无二,差异化壁垒极强 OpenClaw是极少数本地系统级执行、模型无关、纯自托管的终端Agent运行框架,定位“能操作电脑文件、软件、桌面的AI助手”,区别于LangGraph/CrewAI这类后端开发框架、AutoGPT纯实验型智能体。普通办公、个人自动化、小微企业没有替代同类成熟开源工具,C端+中小企业需求持续释放。 社区与生态飞轮已经跑通 GitHub 30万+星标、近千名全球持续贡献者,日均数百条PR/Issue迭代,更新频率行业第一;创始人Peter全职维护,大厂(英伟达、Kimi、MiniMax)主动适配接入; ClawHub官方技能仓库沉淀数千标准化Skill,国内衍生生态(xia345、各类中文技能站、私有化二次改版)持续扩容,形成标准锁定; MIT宽松开源协议,允许企业二次改造、搭建托管服务,大量服务商入局完善配套生态(部署、安全加固、私有化定制)。 行业周期红利:本地终端Agent处于普及早期 2026被行业定义为桌面Agent落地元年,云端大模型成本持续下行、本地Ollama离线模型普及,完美匹配OpenClaw“本地优先”架构;未来3年,个人自动化、企业内网办公自动化需求只会扩张。 短期仅有的可控风险 Token调用成本偏高、频繁更新易出现版本兼容bug、本地高权限带来安全隐患; 以上问题官方正在持续迭代修复,企业级备份、权限沙箱、日志审计功能已逐步补齐,属于可优化痛点,不会动摇存续根基。 结论:未来1–3年是生态最繁荣、流量最大、变现最顺畅的阶段。 二、中期生命力(3~7年,2029–2033):稳定存续,但竞争加剧、增速放缓 存续核心逻辑 标准化生态具备长期锁定效应 SKILL.md、ClawHub统一技能规范、openclaw CLI命令行已经形成行业事实标准。就算出现竞品,开发者、存量数万套技能、企业定制项目迁移成本极高,生态不会短时间崩塌,会维持稳定使用人群。 分层商业模式支撑项目持续维护 原生项目开源免费,但周边商业化闭环成型:企业私有化部署服务、安全审计、托管云服务、垂直行业技能付费、模型渠道分销,持续产生现金流反哺社区开发,不会出现“没人维护停更”的局面。 使用人群分层留存 C端极客、办公自动化爱好者会长期使用; 中小企业内网自动化、数据处理场景高度依赖本地执行Agent,大厂SaaS Agent无法满足内网隐私需求; 开发者持续基于OpenClaw做二次分支、私有化改版,衍生生态会持续分流、延续整个“龙虾生态”的热度。 中期衰减变量(会降低增速,但不会淘汰项目) 微软、苹果、国产操作系统推出原生系统级AI助手,抢占普通小白用户; 新轻量化终端Agent开源框架分流开发者; 各国监管对本地高权限AI自动化工具出台更严格合规要求,提高企业落地门槛; 结论:3–7年不会消亡,但行业从爆发期进入存量竞争,流量红利收窄,平台需要深耕私有化、企业定制、垂直细分赛道才能持续盈利。 三、长期生命力(7年以上,2033之后):分两种极端走向 走向1:长期持续存活(概率60%),变成基础设施级工具 如果行业发展符合以下趋势,OpenClaw会像现在的Python、Git一样长期存续: 终端自主Agent成为电脑标配生产力工具,本地执行、离线隐私是永久刚需; OpenClaw持续完成企业级、合规化改造,成为政企内网自动化标准选型; 社区形成基金会/商业公司承接维护,摆脱单一创始人依赖,实现长久开源运营。 走向2:逐步边缘化、被新一代架构替代(概率40%) 触发条件: 操作系统底层内置标准化Agent执行层,统一API,第三方独立运行框架失去生存空间; 多模态、具身智能技术迭代,全新架构完全替代“技能+本地脚本执行”模式; 全球监管全面限制本地高权限自主AI工具,商用落地基本锁死,仅小众极客圈子留存。 即便被边缘化,存量存量技能、配套站点、私有部署项目仍会维持5–10年长尾生命周期,不会瞬间彻底消失。 四、关键风险:会大幅缩短生命周期的致命隐患 安全重大事故 若出现大规模Skill供应链投毒、批量本地数据泄露事件,企业端市场会快速萎缩,仅保留个人玩家生态;官方正在完善自动病毒扫描、技能审核机制,风险持续降低。 创始人断更、无承接主体 当前项目由Peter单人主导,若后续精力转移、无商业公司接手维护,迭代速度断崖式下滑,竞争力快速落后竞品;目前已有多家AI服务商、模型厂商深度合作,存在接手预期。 算力成本长期居高不下 如果大模型API按量价格无法大幅下降,普通用户长期使用成本过高,会劝退大众用户,仅留存企业付费群体。 国内政策监管收紧 国内针对本地自主自动化工具出台限制,国内衍生生态、配套导航平台流量大幅下滑,但海外生态不受影响。 五、综合最终总结 0–3年(黄金期):放心投入建站、填充内容、运营变现,生态高速扩张,流量红利充足; 3–7年(平稳期):生态稳定存在,竞争变多,需要走差异化(私有化、离线、海外双语)路线维持竞争力; 7年以上(分化期):要么成为长期基础设施永续存在,要么逐步小众长尾,即便衰退也有数年缓冲时间; 整体安全底线:至少拥有5年以上稳定商业运营周期,足够覆盖站点开发、回本、盈利完整周期;中长期只要避开通用综合赛道,主打本地离线私有化细分,生命周期会进一步拉长。

2 个月前
马斯克旗下 xAI 静默上线 Grok 4.3,API 价格下调约 60%,引发行业连锁降价,大模型商业化进入 “低价普惠” 阶段。

3 个月前
AiPPT: 一句话、一分钟、一键搞定

3 个月前
Ralph 就是一个让 AI "自己干活直到做完"的循环机制,特别适合复杂的编程任务,解放人力。这里介绍具体怎么搭建和使用 Ralph 循环。 ? 前置准备 你需要准备以下内容: 工具 用途 Claude Code Anthropic 的 AI 编程助手 CLI Docker Desktop 提供隔离的沙盒环境 Anthropic API Key 调用 Claude API ?️ 搭建步骤 方法一:使用 Claude Code 插件(推荐) Step 1: 安装 Claude Code # 安装 Claude Code CLI npm install -g @anthropic-ai/claude-code Step 2: 初始化项目 mkdir my-ralph-project cd my-ralph-project claude init Step 3: 添加插件市场 claude plugins add-marketplace Step 4: 安装 Ralph Wiggum 插件 claude plugins install ralph-wiggum Step 5: 配置 Stop Hook 在 .claude/hooks/ 目录下创建 stop-hook.json: { "hook_type": "stop", "decision": "block", "conditions": { "check_tests": true, "check_type_errors": true, "check_git_changes": true }, "max_iterations": 20, "prompt": "任务未完成,请继续迭代修复问题" } 方法二:手动搭建(完全控制) Step 1: 创建项目结构 my-ralph-project/ ├── .claude/ │ ├── hooks/ │ │ └── stop-hook.sh │ ├── skills/ │ │ └── ralph-loop.json │ └── config.json ├── prd/ │ └── requirements.json └── workspace/ Step 2: 配置核心文件 config.json - 核心配置 { "max_iterations": 15, "auto_commit": true, "run_tests_after_each_iteration": true, "stop_conditions": { "all_tests_pass": true, "no_type_errors": true, "prd_completed": true } } skills/ralph-loop.json - 技能定义 { "name": "ralph-loop", "description": "自主迭代循环实现 PRD 任务", "trigger": "when_task_incomplete", "actions": [ "analyze_current_state", "identify_blockers", "fix_issues", "run_tests", "commit_if_passing" ] } hooks/stop-hook.sh - Stop Hook 脚本 #!/bin/bash # 检查测试是否通过 TESTS_PASS=$(npm test 2>&1 | grep -c "passed") # 检查是否有类型错误 TYPE_ERRORS=$(npx tsc --noEmit 2>&1 | grep -c "error") # 检查 PRD 是否完成 PRD_COMPLETE=$(node check-prd.js) if || || ; then echo "BLOCK: 任务未完成,继续迭代" exit 1 else echo "ALLOW: 任务已完成" exit 0 fi Step 3: 准备 PRD 文件 prd/requirements.json { "project_name": "My Feature", "tasks": [ { "id": 1, "description": "创建用户登录页面", "criteria": , "status": "pending" }, { "id": 2, "description": "实现用户注册功能", "criteria": , "status": "pending" } ] } ? 使用方法 启动 RALPH 循环 # 方法一:插件方式 claude run --skill ralph-loop --prd ./prd/requirements.json # 方法二:Docker 隔离环境 docker run -it \ -v $(pwd):/workspace \ -e ANTHROPIC_API_KEY=$ANTHROPIC_API_KEY \ claude-ralph:latest 监控循环状态 # 查看当前迭代次数 cat .ralph/iteration_count # 查看任务完成状态 cat .ralph/task_status.json # 查看日志 tail -f .ralph/loop.log ? 高级配置 1. 自定义 Stop Hook 规则 { "stop_conditions": { "all_tests_pass": { "enabled": true, "command": "npm test", "success_pattern": "all tests passed" }, "no_lint_errors": { "enabled": true, "command": "npm run lint", "success_pattern": "no problems" }, "coverage_threshold": { "enabled": true, "threshold": 80 } } } 2. 添加代码审查步骤 { "after_each_iteration": [ "run_tests", "run_linter", "code_review", "commit_if_passing" ], "code_review_prompt": "审查代码质量、安全性、性能问题" } 3. 设置成本控制 { "cost_limits": { "max_tokens_per_iteration": 50000, "max_total_cost": 50, "alert_at_cost": 30 } } ? 典型工作流程 ┌─────────────────────────────────────────────┐ │ 1. Claude 读取 PRD 任务列表 │ └─────────────────┬───────────────────────────┘ ↓ ┌─────────────────────────────────────────────┐ │ 2. 选择下一个待完成任务 │ └─────────────────┬───────────────────────────┘ ↓ ┌─────────────────────────────────────────────┐ │ 3. 实现代码、编写测试 │ └─────────────────┬───────────────────────────┘ ↓ ┌─────────────────────────────────────────────┐ │ 4. 运行测试套件 │ └─────────────────┬───────────────────────────┘ ↓ ┌─────────────────────────────────────────────┐ │ 5. Stop Hook 检查是否完成 │ │ • 测试通过? │ │ • 无类型错误? │ │ • PRD 要求满足? │ └─────────────────┬───────────────────────────┘ ↓ ┌───────┴───────┐ ↓ ↓ 未完成 完成 ↓ ↓ 返回步骤 2 结束循环 ? 最佳实践 建议 说明 PRD 要清晰 任务描述具体、可验证,避免模糊需求 设置最大迭代 防止无限循环消耗过多成本 使用 Docker 隔离环境,避免污染本地系统 定期检查 每 10 轮查看一次进度和日志 成本监控 设置预算警报,避免超支 ⚠️ 注意事项 成本控制:每次迭代消耗 tokens,长时间运行成本较高 质量检查:AI 可能"认为"完成但实际有 bug,需要严格测试 安全边界:在沙盒环境运行,避免 AI 误删重要文件 人工介入:复杂任务仍需人工审查结果










