
Transformer是一种基于自注意力机制的深度神经网络架构,最初在2017年被提出用于机器翻译任务。它完全基于注意力机制,摒弃了之前广泛使用的循环和卷积网络结构。Transformer模型通过其独特的并行化处理能力,在多个领域,包括自然语言处理(NLP)和计算机视觉(CV)中取得了显著的成果。
在NLP领域,Transformer不仅推动了机器翻译的进展,还促进了如BERT这样的预训练语言表示模型的发展。这些模型通过预训练深度双向表示,能够在多种任务上实现最先进的性能,无需对特定任务进行大量架构修改。
在计算机视觉领域,Transformer的应用也日益增多。研究表明,基于Transformer的模型在图像分类、目标检测和图像分割等任务上表现出色。例如,Reformer通过引入局部敏感哈希和可逆残差层技术,提高了Transformer在长序列上的效率和内存使用效率。此外,Inception Transformer通过结合卷积和最大池化操作,有效地捕获了视觉数据中的高低频信息,进一步提升了Transformer在视觉任务上的性能。
1,注意力机制(Self-Attention)
2,Scaled Dot-Product Attention: 通过线性变换和点积计算注意力权重
3,Multi-Head Attention: 使用多个独立的注意力头,提高表征能力
4,编码器-解码器架构
-- Encoder: 包含自注意力子层和全连接前馈神经网络子层,每个层都有残差连接和层归一化
-- Decoder: 包含自注意力子层,用于关注输入序列的表示,通过关注编码器的输出来预测下一个token
-- 位置编码和基于注意力的损失函数
-- Positional Encoding: 将位置信息嵌入到词嵌入向量中,使模型能感知到序列中的顺序
Transformer模型的优劣如下:
Transformer模型广泛应用于多个领域,包括自然语言处理、计算机视觉、语音识别等。其成功在于强大的序列建模能力、对长距离依赖关系的处理以及并行计算特性。
来源:Metaso.cn

11 个月前
T5:Text-to-Text Transfer Transformer

1 年前
DeepSeek FlashMLA是国产AI公司DeepSeek于2025年2月24日开源的首个代码库。这里的MLA是 Multi-Head Latent Attention 的缩写,指的是多头潜在注意力机制。以下是关于FlashMLA的详细介绍: 技术原理 结合创新技术:FlashMLA的架构融合了现代AI研究中的两项关键创新技术,即低秩键值压缩和去耦位置感知注意力路径。通过矩阵分解压缩KV缓存维度,同时保持独立的旋转位置嵌入(RoPE),在不牺牲位置精度的情况下,与传统注意力机制相比,可将内存消耗降低40%-60%。 基于MLA机制:MLA即多层注意力机制,是一种改进的注意力机制,旨在提高Transformer模型在处理长序列时的效率和性能。MLA通过多个头的并行计算,让模型能同时关注文本中不同位置和不同语义层面的信息,从而更全面、更深入地捕捉长距离依赖关系和复杂语义结构。 功能特点 超高处理性能:在H800上可以实现每秒处理3000GB数据,每秒执行580万亿次浮点运算,在H800 SXM5 GPU上运行CUDA 12.6时,可实现理论内存带宽83%的利用率和计算受限配置下91%的峰值浮点运算。 支持混合精度:提供BF16/FP16混合精度支持,可实现高效内存训练和推理。 动态调度优化:基于块的分页系统,利用64元素内存块,可在并发推理请求中动态分配GPU资源,自动根据序列长度和硬件规格调整内核参数。 兼容性良好:通过简单的Python绑定与PyTorch 2.0+兼容。 应用场景 自然语言处理:在聊天机器人、文本生成等实时生成任务中,能加速大语言模型的解码过程,提高模型的响应速度和吞吐量,使回复更快速、流畅。 医疗保健:可用于加速基因组序列分析,如将分析速度从每秒18个样本提升至42个样本。 金融领域:能应用于高频交易模型,使模型的延迟降低63%,提升交易效率和决策速度。 自动驾驶:在自动驾驶的多模态融合网络中,可实现22ms的推理时间,有助于车辆对复杂路况做出快速反应。 意义价值 技术创新:代表了DeepSeek在AI硬件加速领域的深厚积累,是将MLA创新落地到硬件的具体实现,性能指标足以媲美业界顶尖方案如FlashAttention。 推动开源:打破了此前高效解码内核多由科技巨头闭源垄断的局面,为中小企业和研究者提供了“工业级优化方案”,降低了技术门槛,促进更多创新应用的诞生,推动AI行业的开源合作与发展。

1 年前
在 AI 在自然语言处理等任务中,“chunk”可以理解为“组块”。 它指的是将文本或数据分割成较小的、有意义的单元或片段。

1 年前
Meta的Transfusion模型代表了多模态AI领域的一个重要进展,成功地将Transformer架构与扩散模型(Diffusion models)结合起来,实现了对文本和图像的统一处理和生成。

2 年前
云雀模型基于字节神经网络加速器开发,通过便捷的自然语言交互,能够高效地完成互动对话、信息获取、协助创作等任务,还提供了简单的 API 调用,可基于大模型快速搭建属于自己的 AI 应用,进行业务创新。

2 年前
OmniParse:一个人工智能平台,可将任何非结构化数据提取/解析为针对 GenAI (LLM) 应用程序优化的结构化、可操作数据。

8 天前
西门子Xcelerator开放式数字商业平台作为正式发布生态合作伙伴"繁星计划",旨在发挥平台网络效应,与生态伙伴共享知识与技术资源,共创面向客户的解决方案,共赢数字化与低碳化新机遇。
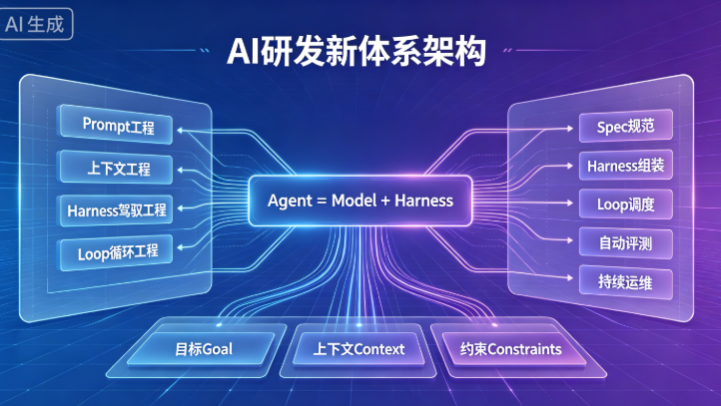
14 天前
AI 研发已从单点 Prompt 优化迭代至Harness 工程底座 + Loop 自治闭环 + SDD 标准化规范的三位一体体系,通过重构人机协作模式,解决大模型落地不稳定、难规模化的痛点,实现企业级 AI 从原型试用走向工程化、自动化、体系化落地。










