
要根据任务需求调整 token 的数量,可以考虑以下几个方面:
1. 明确任务目标和范围:首先要清晰地确定任务的具体内容和所需涵盖的信息范围。如果任务较为简单、明确,可能需要的 token 数量相对较少;若任务复杂、涉及多个方面和细节,就可能需要更多的 token 。
2. 分析输入和输出的复杂度:考虑输入数据的复杂程度和预期输出的详细程度。例如,对于简短的问答任务,输入简短,回答也相对简洁,所需 token 较少;而对于长篇的文本生成任务,如文章写作,就需要更多的 token 来表达丰富的内容。
3. 考虑模型的能力和性能:不同的语言模型对 token 数量的处理能力不同。一些模型在处理大量 token 时可能表现更好,但也可能存在性能下降或计算成本增加的情况。了解所使用模型的特点和限制,有助于合理调整 token 数量。
4. 进行试验和优化:通过多次试验不同的 token 数量设置,观察模型的输出质量和效率。根据试验结果逐步优化 token 数量,找到最适合当前任务的平衡点。
5. 参考类似任务的经验:如果有类似任务的处理经验,可以参考其 token 数量的设置,并根据当前任务的特殊需求进行适当调整。
总之,调整 token 数量需要综合考虑任务的性质、模型的能力以及实际的效果,通过不断尝试和优化来找到最合适的设置。
来源:豆包AI

1 年前
在自然语言处理和人工智能领域,token通常是指文本中的基本单元,比如一个单词、一个标点符号或者一个子词等。100万token的输入输出量是一个较大的数据规模,以下从不同角度来理解这一概念: 从文本长度角度 一般来说,英文中一个单词可以看作一个token,中文可能一个字或一个词作为一个token。如果平均每个token对应5个字符(这只是一个粗略的估计,实际会因语言、文本类型等因素而不同),那么100万token大约对应500万个字符。以一本普通的中文书籍每页约1000字来算,500万个字符相当于5000页的书籍内容,这是非常庞大的文本量。 从处理难度角度 对于语言模型等人工智能系统来说,处理100万token的输入输出意味着要处理大量的信息。模型需要在这么多的token中理解语义、语法关系,捕捉上下文信息等,这对模型的容量、计算能力和算法设计都提出了很高的要求。模型需要有足够多的参数和足够深的网络结构,才能有效地处理如此大规模的文本数据,以生成准确、合理的输出。 处理如此大量的token还需要消耗大量的计算资源和时间。在训练过程中,可能需要使用高性能的GPU或TPU集群,花费数天甚至数周的时间才能完成训练。在推理阶段,也需要较多的计算资源来快速处理输入并生成输出,以满足实时性或高效性的要求。 从应用场景角度 机器翻译:如果用于机器翻译任务,100万token可能包含了各种领域的大量句子和段落。这意味着模型可以学习到丰富的语言表达方式和翻译模式,能够处理更复杂、更专业的翻译任务,提高翻译的准确性和质量。 文本生成:在文本生成任务中,如创作小说、新闻报道等,100万token的输入可以让模型学习到大量的文本风格、主题和结构信息,从而生成更丰富多样、更具创意和逻辑性的文本内容。 智能客服:对于智能客服系统,100万token的输入输出量可以使系统处理大量的用户咨询和问题,学习到各种常见问题的回答模式和解决方案,从而更准确、更快速地为用户提供服务,提高用户满意度。

1 年前
Aleph Alpha无分词器LLM架构创新与应用解析 1️⃣ 创新架构:突破传统分词限制 德国Aleph Alpha公司推出无分词器(tokenizer-free)LLM架构,通过分层字符-词语处理机制解决传统模型痛点: 技术原理:采用轻量级字符编码器将字符序列直接转化为词嵌入,经主干模型处理后由紧凑解码器还原为字符,避免传统分词对低频语言及专业术语的割裂。 核心优势:支持多字母系统(如西里尔文、特殊符号)、小语种及垂直领域知识(法律/医疗术语),训练数据与计算需求降低70%,显著减少碳排放。 2️⃣ 技术联盟:优化生态与可持续性 联合AMD、SiloAI及Schwarz Digits构建技术生态: AMD提供硬件支持:通过优化芯片架构与云资源提升算力效率; SiloAI协同算法开发:压缩模型规模并加速推理过程; 商业场景验证:Lidl母公司数字部门推动零售等行业的本地化应用测试。 3️⃣ 欧洲中心战略:深耕专业与政务市场 聚焦欧洲多语言与合规需求,推出两大方向: 政府智能化:开发专用AI操作系统"Pharia",强化公共数据安全与多语言服务能力; 垂直领域渗透:针对金融、医疗等专业场景提供低能耗、高精度模型,规避依赖GPT系列的数据出境风险。 意义:该架构通过技术底层革新,降低LLM进入门槛,推动欧洲本土AI生态独立发展,同时以环保效益回应全球可持续计算趋势。
1 年前
在语言大模型中,字节(Byte)、字符(Character)和Token是三个不同的概念,它们在文本处理中扮演着不同的角色。以下是它们的详细区别: 1. 字节(Byte) 定义:字节是计算机存储和传输数据的基本单位,通常由8位二进制数组成,可以表示256种不同的值。 用途:字节用于存储和传输文本、图像、音频等数据。在文本处理中,字节用于表示字符的编码。 编码:不同的字符编码标准(如ASCII、UTF-8、UTF-16)使用不同数量的字节来表示字符。例如,ASCII编码中,一个字符通常占用1个字节,而在UTF-8编码中,一个字符可能占用1到4个字节。 2. 字符(Character) 定义:字符是文本的基本单位,可以是字母、数字、标点符号、空格等。字符是人类可读的文本元素。 用途:字符用于表示和显示文本内容。在文本处理中,字符是语言模型处理的基本单位之一。 编码:字符在计算机中通过编码标准(如Unicode)表示。不同的编码标准决定了字符如何映射到字节序列。例如,字符“A”在ASCII编码中表示为65(一个字节),而在UTF-8编码中也表示为65(一个字节)。 3. Token 定义:Token是语言模型处理文本时的基本单位,通常由模型的分词器(Tokenizer)将文本分割成更小的单元。Token可以是单个字符、单词、子词(subword)或符号。 用途:Token用于语言模型的输入和输出。模型通过处理Token序列来理解和生成文本。Token化是语言模型预处理文本的关键步骤。 分词:不同的语言模型使用不同的分词策略。例如,BERT模型使用WordPiece分词器,GPT模型使用Byte Pair Encoding(BPE)分词器。这些分词器将文本分割成适合模型处理的Token序列。 区别总结 字节:计算机存储和传输的基本单位,用于表示字符的编码。 字符:文本的基本单位,人类可读的文本元素。 Token:语言模型处理文本时的基本单位,由分词器将文本分割成适合模型处理的单元。 示例 假设有以下文本:“Hello, 世界!” 字节:在UTF-8编码中,“Hello, 世界!”可能表示为48 65 6C 6C 6F 2C 20 E4 B8 96 E7 95 8C 21(每个字符占用1到3个字节)。 字符:文本中的字符为“H”, “e”, “l”, “l”, “o”, “,”, “ ”, “世”, “界”, “!”。 Token:使用BERT的WordPiece分词器,Token可能为。 通过理解字节、字符和Token的区别,可以更好地理解语言模型如何处理和生成文本。
1 年前
在 AI 语言模型中,Token 的大小并不是固定的字节数。 一般而言,一个简单的英文单词可能算作一个 Token,一个汉字有时也会被当作一个 Token。但像一些常见的短语、专有名词等可能会被视为一个 Token。 大致来说,1000 Token 可能包含几百个单词,或者几百个汉字,具体数量会因语言的复杂性、文本的内容等因素而有所不同。 例如,一段比较简洁明了、没有复杂表述的英文文本,1000 Token 可能包含约 700 - 800 个单词;而对于内容较为丰富、包含较多专业术语或复杂句式的文本,1000 Token 所包含的单词数量可能会更少。 对于中文,由于汉字的信息量相对较大,1000 Token 大约能涵盖 600 - 700 个汉字左右的文本量,但同样会受到文本特点的影响。
2 年前
在调用大模型时,输入价格和输出价格是指在使用大模型进行文本生成或其他任务时,对于输入文本和输出文本所收取的费用。
2 年前
在自然语言处理(NLP)中,token是指文本中最小的语义单元。比如,一个句子可以被分割成若干个单词,每个单词就是一个token。

8 天前
西门子Xcelerator开放式数字商业平台作为正式发布生态合作伙伴"繁星计划",旨在发挥平台网络效应,与生态伙伴共享知识与技术资源,共创面向客户的解决方案,共赢数字化与低碳化新机遇。
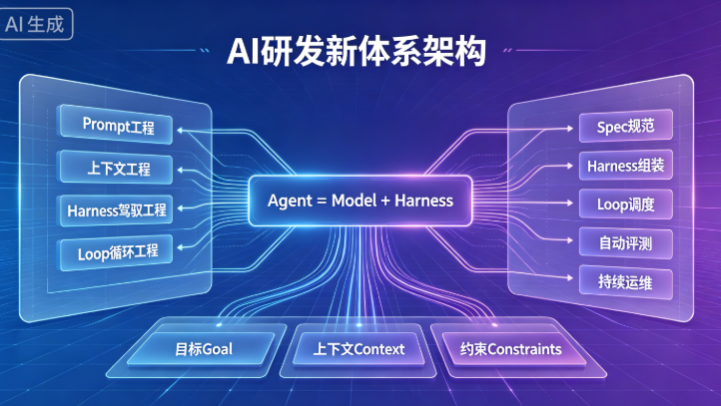
14 天前
AI 研发已从单点 Prompt 优化迭代至Harness 工程底座 + Loop 自治闭环 + SDD 标准化规范的三位一体体系,通过重构人机协作模式,解决大模型落地不稳定、难规模化的痛点,实现企业级 AI 从原型试用走向工程化、自动化、体系化落地。










