

Clipfly是一个由成都恒图科技开发的一站式AI视频制作平台,旨在为用户提供从创意产生到完成视频的全套解决方案。它的核心设计理念是打造一个All-in-one的工具平台,让用户无需在多个AI工具之间频繁切换,就能完成整个视频创作流程。
下面这个表格整理了它的核心信息,帮你快速了解:
| 项目 | 说明 |
|---|---|
| 核心定位 | 一站式AI视频制作平台 |
| 主要特点 | All-in-one工作流,集成了AI生成、编辑、增强等多种功能 |
| 开发公司 | 成都恒图科技(也是知名AI图像工具Fotor的开发者) |
| 核心功能 | AI视频生成、AI视频增强、视频编辑、照片动画、AI虚拟人口播等 |
| 使用模式 | 基于积分的免费和付费模式 |
Clipfly集成了多种实用功能,试图覆盖视频创作的全流程:
Clipfly采用积分制的免费增值模式:
Clipfly是一个功能全面的AI视频创作平台,尤其适合不希望在不同工具间频繁切换的初学者,或者需要快速制作社交媒体视频、营销内容的用户。
如果你正在寻找一个集成了多种AI视频工具的一站式平台,Clipfly值得一试。建议可以先利用免费积分体验其核心功能,看看生成效果是否符合你的预期。
免责声明:本网站仅提供网址导航服务,对链接内容不负任何责任或担保。

9 个月前
2025年10月29日,苹果公司发布了名为Pico-Banana-400K的大规模研究数据集,旨在推动文本引导图像编辑技术的发展。 数据集概况:Pico-Banana-400K包含40万张图像,其研究论文题为《Pico-Banana-400K:面向文本引导图像编辑的大规模数据集》。该数据集采用非商业性研究许可发布,学术机构和研究人员可免费使用。 构建过程:研究团队首先从OpenImages数据集中选取大量真实照片,以确保图像内容的多样性,涵盖人物、物体及含文字场景等。然后设计了35种不同类型的图像修改指令,将其归入像素与光度调整、以人为中心的编辑、场景构成与多主体编辑等八大类别。接着,把原始图像与编辑指令输入至Nanon-Banana模型进行图像编辑,生成结果由Gemini 2.5-Pro模型进行自动评估,只有通过双重验证的结果才会被纳入最终数据集。 数据集构成: 单轮监督微调整子集:包含25.8万个成功的单轮图像编辑示例,涵盖了35种编辑分类法的全部范围,为模型训练提供强大的监督信号。 多轮编辑集:包含7.2万个按顺序进行的编辑交互示例,序列长度从2到5轮不等,用于研究连续修改中的顺序编辑、推理与规划。 偏好集:包含5.6万个示例,由原始图像、指令、成功编辑和失败编辑组成的三联体,可用于训练奖励模型和应用直接偏好优化等对齐技术。 长短指令配对集:用于发展指令重写与摘要能力。 发布意义:尽管Nanon-Banana在精细空间控制、布局外推和文字排版处理方面仍存在局限,但Pico-Banana-400K为下一代文本引导图像编辑模型提供了一个坚实、可复现的训练与评测基础。目前,相关研究论文已发布于预印本平台arXiv,完整的Pico-Banana-400K数据集也已在GitHub上向全球研究者免费开放。 (新闻来源:github.com/apple/pico-banana-400k )

1 年前
AI视频生成模型的主要技术原理包括多种深度学习和机器学习技术,尤其是生成对抗网络(GANs)、变分自编码器(VAEs)和自然语言处理(NLP)。
1 年前
语言大模型(LLM)能够生成图片和视频的能力主要依赖于其多模态学习和生成技术。
1 年前
英伟达在AI和计算领域的多项创新应用与解决方案,涵盖了从数字人类构建、生成式AI集成、到药物发现模拟等多个方面。
1 年前
Meta推出了其 “分割一切AI” 的第二代——SAM2,不仅能实时处理任意长度的视频,连视频中从未见过的物体也能轻松分割追踪。

8 天前
西门子Xcelerator开放式数字商业平台作为正式发布生态合作伙伴"繁星计划",旨在发挥平台网络效应,与生态伙伴共享知识与技术资源,共创面向客户的解决方案,共赢数字化与低碳化新机遇。
14 天前
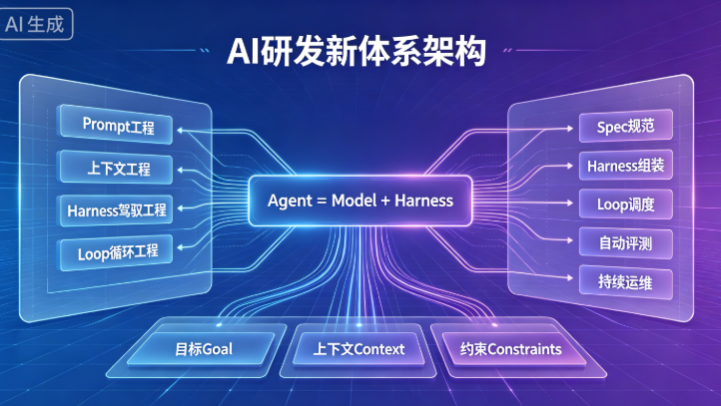
AI 研发已从单点 Prompt 优化迭代至Harness 工程底座 + Loop 自治闭环 + SDD 标准化规范的三位一体体系,通过重构人机协作模式,解决大模型落地不稳定、难规模化的痛点,实现企业级 AI 从原型试用走向工程化、自动化、体系化落地。

18 天前
WorkBuddy有望拿下国内独立桌面自动化办公智能体细分第一。但受企业协同生态、移动端能力等短板限制,无法成为全域企业及全球办公AI赛道第一名,将与钉钉悟空、WPS AI形成差异化竞争格局。



















