

敏捷开发(Agile)已经不是一个新鲜词。从2001年《敏捷宣言》发布至今,我们学会了站会、看板、用户故事和Scrum。但在大数据和AI的浪潮下,许多团队发现:我们引以为傲的“敏捷”,正在变得“迟钝”。
传统的敏捷依赖“人”的经验与直觉。但在数据洪流面前,产品经理无法凭直觉写出完美的需求,Scrum Master无法凭经验感知代码深处的坏味道,开发人员被无穷无尽的数据清洗和特征工程淹没。
数字化转型的现实是残酷的: 如果检视能力受限于人脑带宽,适应速度跟不上数据洪流,敏捷循环就会失速。
那么,在这个算力觉醒的时代,我们该如何重构敏捷?答案不是简单地增加人手,而是将AI植入敏捷的DNA,构建“数据智能混合驱动”的敏捷2.0。
今天,我想和大家探讨一套“大数据AI时代敏捷开发”的新方法论。
核心理念:从“经验驱动”到“数据+算法”双轮驱动
传统敏捷的核心是“透明-检视-适应”。在大数据时代,这套逻辑需要升级。
以前我们看Jira里的任务状态,现在我们要看数据血缘和代码健康度。
痛点: 数据来源杂乱(APP、网页、IoT),格式五花八门,人工标注慢如蜗牛。
解法: 利用AI建立“智能数据管道”。通过自动化工具(如Great Expectations)定义数据质量规则,像“患者年龄必须在18-100岁”这种业务逻辑,由AI自动拦截异常数据。让数据的质量和流转状态对所有人完全透明。
以前我们靠Sprint回顾会议来总结问题,现在我们要靠AI预测来预防问题。
痛点: 技术债积重难返,直到系统崩溃才被发现;测试环境不稳定,拖慢迭代速度。
解法: 引入“项目健康度仪表盘”。利用机器学习分析历史数据,AI能提前预警:某个核心模块的代码复杂度正在飙升,可能成为下一个Bug重灾区;或者识别出某个Sprint的延期风险。Scrum Master不再只是“会议主持人”,而是“组织健康教练”,看着仪表盘上的黄灯主动介入。
以前我们根据用户反馈调整下个迭代的计划,现在我们要实时响应数据反馈。
痛点: 模型训练耗时数小时甚至数天,严重拖慢节奏。
解法: 建立“敏捷迭代闭环”(Agile Iteration Loop)。就像厨师试菜谱,利用DevOps自动化链路,将“数据准备-模型训练-评估-调整”的过程自动化。试错速度从“天”缩短到“小时”,一天能验证8次假设,而不是以前的3次。
️实战法则:大数据AI时代的“新六艺”
在这一部分,我为大家总结了落地这套新范式的六大实战法则:
产品经理(PO)往往受限于个人认知偏见。
数据是AI的燃料,但也是敏捷的最大瓶颈。
模型开发不能像科研一样无休止探索。
代码生成只是AI的初级应用,真正的未来是AutoDev(自动化软件开发)。
这是很多团队最容易忽视的“红线”。
技术可以引进,文化必须重塑。
结语:敏捷从未过时,它只是在进化
大数据和AI并没有杀死敏捷,相反,它在倒逼敏捷进化。
未来的敏捷开发,不再是单纯靠“人肉”的快速响应,而是基于数据智能的“涌现式”响应。我们不再试图预测未来,而是通过极快的反馈闭环,让价值在一次次迭代中自然“涌现”。
在这个时代,“数据是新的代码,模型是新的功能”。希望这套融合了AI与大数据思维的敏捷新范式,能帮助你在数字化转型的深水区,不仅生存下来,更能游刃有余。
让我们一起,从“人肉敏捷”走向“智能涌现”。

7 个月前
具身AI是AGI的核心系统范式,将智能从网络空间扩展到物理实体,是认知科学与神经科学的产物。

1 年前
德国人工智能研究的高校重镇 德国作为工业强国,在人工智能领域也具有深厚的底蕴和领先地位。众多德国高校在AI研究方面投入了大量资源,取得了丰硕成果。

1 年前
Amazon Q是一款功能最强大的生成式 AI 助手,用于加速软件开发和利用业务数据。

9 天前
西门子Xcelerator开放式数字商业平台作为正式发布生态合作伙伴"繁星计划",旨在发挥平台网络效应,与生态伙伴共享知识与技术资源,共创面向客户的解决方案,共赢数字化与低碳化新机遇。
14 天前
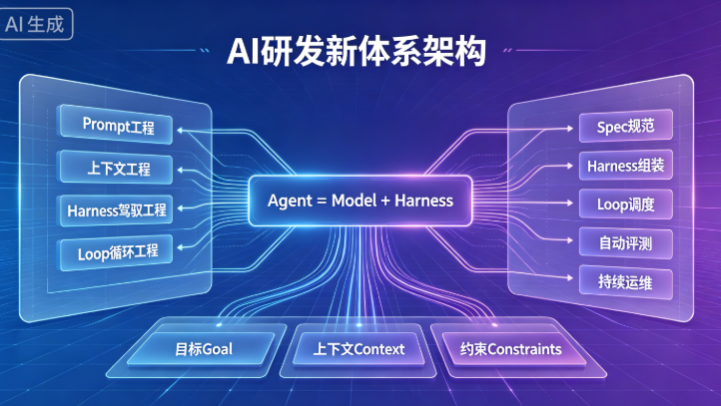
AI 研发已从单点 Prompt 优化迭代至Harness 工程底座 + Loop 自治闭环 + SDD 标准化规范的三位一体体系,通过重构人机协作模式,解决大模型落地不稳定、难规模化的痛点,实现企业级 AI 从原型试用走向工程化、自动化、体系化落地。

19 天前
WorkBuddy有望拿下国内独立桌面自动化办公智能体细分第一。但受企业协同生态、移动端能力等短板限制,无法成为全域企业及全球办公AI赛道第一名,将与钉钉悟空、WPS AI形成差异化竞争格局。

26 天前
OpenClaw工具与生态完整生命周期判断 本文尝试分短期、中期、长期三段,结合项目现状、风险、护城河客观测算OpenClaw这款智能体工具或者相似工具的发展趋势。 一、短期生命力(1~3年,2026–2029):完全安全、高速增长,是黄金运营窗口期 支撑理由 赛道刚需独一无二,差异化壁垒极强 OpenClaw是极少数本地系统级执行、模型无关、纯自托管的终端Agent运行框架,定位“能操作电脑文件、软件、桌面的AI助手”,区别于LangGraph/CrewAI这类后端开发框架、AutoGPT纯实验型智能体。普通办公、个人自动化、小微企业没有替代同类成熟开源工具,C端+中小企业需求持续释放。 社区与生态飞轮已经跑通 GitHub 30万+星标、近千名全球持续贡献者,日均数百条PR/Issue迭代,更新频率行业第一;创始人Peter全职维护,大厂(英伟达、Kimi、MiniMax)主动适配接入; ClawHub官方技能仓库沉淀数千标准化Skill,国内衍生生态(xia345、各类中文技能站、私有化二次改版)持续扩容,形成标准锁定; MIT宽松开源协议,允许企业二次改造、搭建托管服务,大量服务商入局完善配套生态(部署、安全加固、私有化定制)。 行业周期红利:本地终端Agent处于普及早期 2026被行业定义为桌面Agent落地元年,云端大模型成本持续下行、本地Ollama离线模型普及,完美匹配OpenClaw“本地优先”架构;未来3年,个人自动化、企业内网办公自动化需求只会扩张。 短期仅有的可控风险 Token调用成本偏高、频繁更新易出现版本兼容bug、本地高权限带来安全隐患; 以上问题官方正在持续迭代修复,企业级备份、权限沙箱、日志审计功能已逐步补齐,属于可优化痛点,不会动摇存续根基。 结论:未来1–3年是生态最繁荣、流量最大、变现最顺畅的阶段。 二、中期生命力(3~7年,2029–2033):稳定存续,但竞争加剧、增速放缓 存续核心逻辑 标准化生态具备长期锁定效应 SKILL.md、ClawHub统一技能规范、openclaw CLI命令行已经形成行业事实标准。就算出现竞品,开发者、存量数万套技能、企业定制项目迁移成本极高,生态不会短时间崩塌,会维持稳定使用人群。 分层商业模式支撑项目持续维护 原生项目开源免费,但周边商业化闭环成型:企业私有化部署服务、安全审计、托管云服务、垂直行业技能付费、模型渠道分销,持续产生现金流反哺社区开发,不会出现“没人维护停更”的局面。 使用人群分层留存 C端极客、办公自动化爱好者会长期使用; 中小企业内网自动化、数据处理场景高度依赖本地执行Agent,大厂SaaS Agent无法满足内网隐私需求; 开发者持续基于OpenClaw做二次分支、私有化改版,衍生生态会持续分流、延续整个“龙虾生态”的热度。 中期衰减变量(会降低增速,但不会淘汰项目) 微软、苹果、国产操作系统推出原生系统级AI助手,抢占普通小白用户; 新轻量化终端Agent开源框架分流开发者; 各国监管对本地高权限AI自动化工具出台更严格合规要求,提高企业落地门槛; 结论:3–7年不会消亡,但行业从爆发期进入存量竞争,流量红利收窄,平台需要深耕私有化、企业定制、垂直细分赛道才能持续盈利。 三、长期生命力(7年以上,2033之后):分两种极端走向 走向1:长期持续存活(概率60%),变成基础设施级工具 如果行业发展符合以下趋势,OpenClaw会像现在的Python、Git一样长期存续: 终端自主Agent成为电脑标配生产力工具,本地执行、离线隐私是永久刚需; OpenClaw持续完成企业级、合规化改造,成为政企内网自动化标准选型; 社区形成基金会/商业公司承接维护,摆脱单一创始人依赖,实现长久开源运营。 走向2:逐步边缘化、被新一代架构替代(概率40%) 触发条件: 操作系统底层内置标准化Agent执行层,统一API,第三方独立运行框架失去生存空间; 多模态、具身智能技术迭代,全新架构完全替代“技能+本地脚本执行”模式; 全球监管全面限制本地高权限自主AI工具,商用落地基本锁死,仅小众极客圈子留存。 即便被边缘化,存量存量技能、配套站点、私有部署项目仍会维持5–10年长尾生命周期,不会瞬间彻底消失。 四、关键风险:会大幅缩短生命周期的致命隐患 安全重大事故 若出现大规模Skill供应链投毒、批量本地数据泄露事件,企业端市场会快速萎缩,仅保留个人玩家生态;官方正在完善自动病毒扫描、技能审核机制,风险持续降低。 创始人断更、无承接主体 当前项目由Peter单人主导,若后续精力转移、无商业公司接手维护,迭代速度断崖式下滑,竞争力快速落后竞品;目前已有多家AI服务商、模型厂商深度合作,存在接手预期。 算力成本长期居高不下 如果大模型API按量价格无法大幅下降,普通用户长期使用成本过高,会劝退大众用户,仅留存企业付费群体。 国内政策监管收紧 国内针对本地自主自动化工具出台限制,国内衍生生态、配套导航平台流量大幅下滑,但海外生态不受影响。 五、综合最终总结 0–3年(黄金期):放心投入建站、填充内容、运营变现,生态高速扩张,流量红利充足; 3–7年(平稳期):生态稳定存在,竞争变多,需要走差异化(私有化、离线、海外双语)路线维持竞争力; 7年以上(分化期):要么成为长期基础设施永续存在,要么逐步小众长尾,即便衰退也有数年缓冲时间; 整体安全底线:至少拥有5年以上稳定商业运营周期,足够覆盖站点开发、回本、盈利完整周期;中长期只要避开通用综合赛道,主打本地离线私有化细分,生命周期会进一步拉长。

2 个月前
马斯克旗下 xAI 静默上线 Grok 4.3,API 价格下调约 60%,引发行业连锁降价,大模型商业化进入 “低价普惠” 阶段。








