
一种全新的大语言模型(LLM)架构有望代替至今在 AI 领域如日中天的 Transformer,性能也比 Mamba 更好。2024年7月8日,有关 Test-Time Training(TTT)的论文成为了人工智能社区热议的话题。

斯坦福大学、加州大学伯克利分校、加州大学圣地亚哥分校和Meta的学者提出了一种全新架构,希望能用机器学习模型取代RNN的隐藏状态。这个架构通过对输入token进行梯度下降来压缩上下文,被称为“测试时间训练层(Test-Time-Training layers,简称TTT层)”。“共同一作”加州大学伯克利分校的Karen Dalal表示,我相信这将从根本上改变语言模型。
在机器学习模型中,TTT 层直接取代 Attention,并通过表达性记忆解锁线性复杂性架构,使我们能够在上下文中训练具有数百万(有时是数十亿)个 token 的 LLM。
在 125M 到 1.3B 参数规模的大模型上进行了一系列对比发现,TTT-Linear 和 TTT-MLP 均能匹敌或击败最强大的 Transformers 和 Mamba 架构方法。
TTT 层作为一种新的信息压缩和模型记忆机制,可以简单地直接替代 Transformer 中的自注意力层。

过去这些年来,对大模型的研究和理解都绕不开“循环神经网络(RNN)”。RNN是一种深度学习模型,由许多相互连接的组件组成,经过训练后可以处理顺序数据输入并将其转换为特定的顺序数据输出,例如将文本从一种语言翻译成另一种语言。顺序数据是指单词、句子或时间序列数据之类的数据,其中的顺序分量根据复杂的语义和语法规则相互关联。
而“隐藏状态”是RNN模型中的一个关键概念。它可以看作是网络在每个时间步骤上的“记忆”,存储了之前时间步骤中的信息,并通过时间在不同步骤之间传递。隐藏状态可以捕捉到序列中的长期依赖性,从而使模型能够理解整个序列的上下文。
在传统的RNN中,隐藏状态的固定大小表达能力受限,也不好并行训练。例如,像Mamba这样的RNN层,会随着时间的推移压缩成一个固定大小的状态,它们虽然效率很高,但性能受限于其表达能力。
这个研究团队的对TTT层的想法来自于:与其让RNN隐藏状态被动地储存信息,不如让它主动学习。**设计的“TTT层”突破了“RNN层”在长上下文中性能受限的问题。**
他们在1.25亿~ 13亿个参数规模的大模型上进行一系列的对比后发现,TTT-Linear(线性模型)和TTT-MLP (MLP为多层感知器,基于前馈神经网络的深度学习模型)均能匹敌或击败最强大的Transformers和 Mamba架构方法。
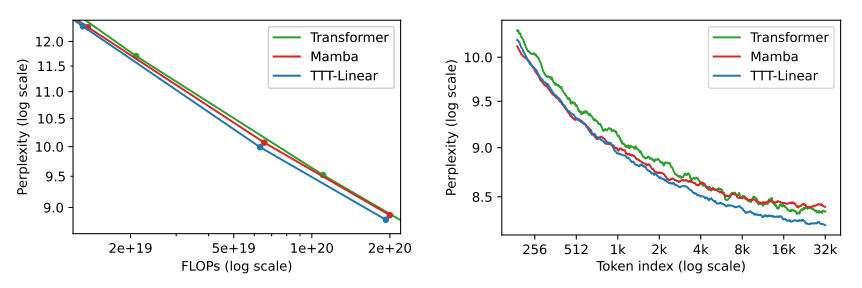
隐藏状态时线性模型的TTT-Linear表现超过了Transformer和Mamba,用更少的算力达到更低的困惑度(下图左),也能更好利用长上下文(下图右)。此外,隐藏状态时MLP模型的TTT-MLP在32k长上下文时表现还要更好。
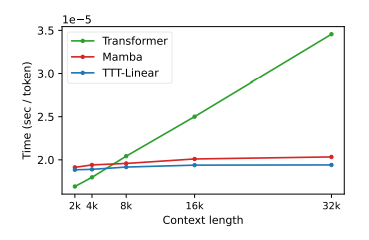
在实际运行时间上,TTT模型也比Transformer和Mamba更快。
更多详细内容,可参见[https://arxiv.org/abs/2407.04620]

2 个月前
马斯克旗下 xAI 静默上线 Grok 4.3,API 价格下调约 60%,引发行业连锁降价,大模型商业化进入 “低价普惠” 阶段。

5 个月前
Xiaomi-Robotics-0 预训练了大量跨身体机器人轨迹和视觉语言数据,使其能够获得广泛且可推广的动作生成知识,同时保持强大的VLM能力。

5 个月前
AI Agent 的真正智能,来自于知识获取(RAG) + 协作协议(MCP) + 执行能力(SKILLS)的统一协同,而不是单一大模型孤立输出。

6 个月前
命令优先,而非图形界面。

6 个月前
这正是当前 AI 视频生成领域最前沿的突破方向。你提出的这个问题,本质上是在问如何让 AI 从“画皮”进阶到“画骨”——即不仅画面好看,运动逻辑也要符合现实世界的物理法则。 结合最新的技术进展(如 2025 年的相关研究),要让 AI 生成符合真实规律的视频,我们可以通过以下几种“高级语言描述法”来与模型沟通: 1. 使用“力提示”技术:像导演一样指挥物理力 ? 这是谷歌 DeepMind 等团队提出的一种非常直观的方法。你不需要懂复杂的物理公式,只需要在提示词中描述“力”的存在。 描述力的方向与强度: 你可以直接告诉 AI 视频中存在某种力。例如,不只是写“旗帜飘动”,而是写“旗帜在强风中剧烈飘动”或“气球被轻轻向上吹起”。 区分全局力与局部力: 全局力(风、重力): 影响整个画面。例如:“Global wind force blowing from left to right”(从左到右的全局风力)。 局部力(碰撞、推力): 影响特定点。例如:“A ball rolling after being kicked”(球被踢后滚动)。 效果: AI 模型(如 CogVideoX 结合特定模块)能理解这些力的矢量场,从而生成符合动力学的运动,比如轻的物体被吹得更远,重的物体移动缓慢。 2. 调用“思维链”与物理常识:让 LLM 当质检员 ? 有时候直接描述很难精准,我们可以借助大型语言模型(LLM)作为“中间人”来审核物理逻辑。这种方法(如匹兹堡大学的 PhyT2V)利用 LLM 的推理能力。 分步描述(Chain-of-Thought): 你可以在提示词中要求 AI “思考过程”。例如,不只是生成“水倒入杯子”,而是引导它:“首先,水从壶嘴流出,形成抛物线;然后,水撞击杯底,产生涟漪;最后,水位上升,流速减慢。” 明确物理规则: 在提示词中直接嵌入物理常识。例如:“根据重力加速度,球下落的速度应该越来越快”或“流体具有粘性,流动时会有拉丝效果”。 回溯修正: 如果第一版视频不符合物理规律(比如球浮在空中),你可以通过反馈指令让系统进行“回溯推理”,识别出视频与物理规则的语义不匹配,并自动修正提示词重新生成。 3. 参数化控制:像物理老师一样给定数值 ? 如果你需要极其精确的物理运动(例如做科学实验模拟或电影特效),可以使用类似普渡大学 NewtonGen 框架的思路,直接给定物理参数。 设定初始状态: 在语言描述中包含具体的物理量。 位置与速度: “一个小球从坐标 (0, 10) 以初速度 5m/s 水平抛出”。 角度与旋转: “一个陀螺以角速度 10rad/s 旋转”。 质量与材质: “一个轻质的泡沫块”与“一个沉重的铁球”在相同力作用下的反应是不同的。 指定运动类型: 明确指出是“匀速直线运动”、“抛物线运动”还是“圆周运动”。AI 会根据这些语义,调用内置的“神经物理引擎”来计算轨迹,确保视频中的物体运动轨迹符合牛顿定律。 4. 结合物理引擎的混合描述:虚实结合 ? 更高级的方法是让语言描述直接驱动物理模拟器(如 Blender, Genesis),然后将结果渲染成视频。 描述物理属性: 在提示词中指定物体的密度、弹性系数、摩擦力等。 事件驱动描述: 描述物体间的相互作用。例如:“一个刚性的小球撞击一个柔软的布料,布料发生形变并包裹住小球”。 通用物理引擎: 像 Genesis 这样的新模型,允许你用自然语言描述复杂的物理场景(如“一滴水滑落”),它能直接生成符合流体动力学的模拟数据,而不仅仅是看起来像视频的图像帧。 ? 总结:如何写出“物理级”提示词? 为了更直观地掌握这种描述方式,这里总结了一个对比表: 一句话总结: 要用语言描述物理运动,关键在于将“视觉结果”转化为“物理过程”。多用描述力(风、推力)、属性(重力、粘性)、参数(速度、角度)的词汇,甚至直接告诉 AI 要遵循某种物理规律,这样生成的视频才会有真实的“重量感”和“真实感”。

6 个月前
利用大语言模型(LLM)构建虚拟的“世界模型”(World Models),以此作为 KI 智能体(AI Agents)积累经验和训练的场所。 核心概念:让 LLM 成为 AI 的“模拟练习场” 目前,开发能在现实世界执行复杂任务的 AI 智能体(如机器人、自动化软件助手)面临一个巨大挑战:获取实际操作经验的成本极高且充满风险。 如果让机器人在物理世界中通过“试错”来学习,不仅效率低下,还可能造成硬件损毁。 研究人员提出的新思路是:利用已经掌握了海量人类知识的大语言模型(LLM),由它们通过文字或代码生成一个模拟的“世界模型”。 1. 什么是“世界模型”? 世界模型是一种模拟器,它能预测特定行为可能产生的结果。 传统方式: 需要开发者手动编写复杂的代码来定义物理法则和环境规则。 LLM 驱动方式: 预训练的大模型(如 GPT-4 或 Claude)已经具备了关于世界运行逻辑的知识(例如:知道“推倒杯子水会洒”)。研究人员可以利用 LLM 自动生成这些模拟环境的逻辑。 2. 研究的具体内容 来自上海交通大学、微软研究院、普林斯顿大学和爱丁堡大学的国际研究团队对此进行了深入研究。他们测试了 LLM 在不同环境下充当模拟器的能力: 家庭模拟(Household Simulations): 模拟洗碗、整理房间等日常任务。 电子商务网站(E-Commerce): 模拟购物行为、库存管理等逻辑。 3. 关键发现: 强结构化环境表现更佳: 在规则清晰、逻辑严密的场景(如简单的文本游戏或特定流程)中,LLM 驱动的模拟效果非常好。 开放世界的局限性: 对于像社交媒体或复杂的购物网站这类高度开放的环境,LLM 仍需要更多的训练数据和更大的模型参数才能实现高质量的模拟。 真实观察的修正: 实验显示,如果在 LLM 模拟器中加入少量来自现实世界的真实观察数据,模拟的质量会显著提升。 对 AI 行业的意义 加速 AI 智能体进化: 这种方法让 AI 智能体可以在几秒钟内完成数千次的虚拟实验,极大加快了学习速度。 降低训练门槛: 开发者不再需要搭建昂贵的物理实验室,只需要调用 LLM 接口就能创建一个“训练场”。 2026 年的趋势: 这预示着 2026 年及以后,“自主智能体”将成为 AI 发展的核心,而这种“基于模拟的学习”将是通往通用人工智能(AGI)的关键一步。 总结 该研究证明,LLM 不仅仅是聊天机器人,它们可以演变成复杂的“数字世界创造者”。在这个虚拟世界里,新一代的 AI 智能体可以安全、低成本地反复磨练技能,最终再将学到的能力应用到现实生活和工作中。 ( 根据海外媒体编译 )

7 个月前
Nova 2是亚马逊于2025年12月在re:Invent 全球大会上推出的新一代基础模型家族,共包含4款模型,均需通过Amazon Bedrock平台使用,兼顾行业领先的性价比与多场景适配性,具体介绍如下 : 1. Nova 2 Lite: 主打快速、高性价比的日常推理任务,可处理文本、图像和视频输入并生成文本。能通过调节“思考”深度平衡智能、速度与成本,适合客服聊天机器人、文档处理等场景。在基准测试中,它对标Claude Haiku 4.5、GPT - 5 Mini等模型,多数项目表现持平或更优。 2. Nova 2 Pro(预览版): 是该家族中智能度最高的推理模型,可处理文本、图像、视频和语音输入并生成文本。适配代理编码、长期规划等复杂任务,还能作为“教师模型”向小型模型传递能力,在与Claude Sonnet 4.5、Gemini 2.5 Pro等主流模型的对比中,多项基准测试表现出色。 3. Nova 2 Sonic: 专注端到端语音交互的模型,能实现类人化实时对话。它支持多语言与丰富音色,拥有100万token上下文窗口,可支撑长时交互,还能与Amazon Connect等语音服务、对话框架无缝集成,适配客服、AI助手等语音场景。 4. Nova 2 Omni: 业内首款统一多模态推理与生成模型,可处理文本、图像等多种输入,还能同时生成文本和图像。它能一次性处理海量多格式内容,比如数百页文档、数小时音频等,适合营销素材一站式制作等需要整合多类信息的场景。 这4款模型均具备100万token上下文窗口,且内置网页查找和代码执行能力,能保障回答的时效性与实用性 。

8 个月前
LoRA(Low-Rank Adaptation)是一种对大模型进行“轻量级微调”的技术。










