
LoRA(Low-Rank Adaptation)是一种高效的微调技术,主要用于大型预训练语言模型的适应和优化。其核心思想是通过引入少量的额外参数来实现模型的微调,而不是改变模型的全部参数。具体来说,LoRA通过对大型模型的权重矩阵进行隐式的低秩转换,从而降低计算和存储的开销。
LoRA的主要优势在于它能够大幅降低微调过程中所需的GPU资源需求和计算复杂度。此外,LoRA通过在原始预训练语言模型旁边增加一个旁路,并训练降维与升维矩阵来模拟内在秩,实现了高效的参数微调。这种方法不仅减少了参数量,还节省了显存,使得训练好的权重可以合并到原始权重上,推理架构不需要作出改变。
例如,在GPT-3 175B模型上,LoRA可以将可训练参数数量减少10,000倍,同时将GPU内存需求减少3倍。尽管LoRA减少了可训练参数的数量,但它在RoBERTa、DeBERTa、GPT-2和GPT-3等模型上的性能表现与全参数微调相当或更好。这表明LoRA不仅提高了效率,而且保持了模型的质量。
然而,LoRA也存在一些局限性。例如,LoRA块的大小是固定的,不能在训练后修改(如果需要改变LoRA块的秩,则必须从头开始重新训练)。此外,优化LoRA块的秩需要大量的搜索和努力。为了解决这些问题,研究者提出了动态低秩适应(DyLoRA)技术,该技术通过在不同秩下对适配器模块的学习表示进行排序,训练一系列秩的LoRA块,从而至少可以将训练速度提高4到7倍,而且不会显著牺牲性能。
此外,还有研究提出了通用化的LoRA(GLoRA),它通过使用一个通用的提示模块来优化预训练模型权重并调整中间激活,提供了更多的灵活性和能力,适用于多种任务和数据集。GLoRA还采用了可扩展的、模块化的、逐层结构搜索,学习每个层的个体适配器,展示了强大的迁移学习、少样本学习和领域泛化能力。
LoRA定义
低秩适应方法
用于大型预训练语言模型的适应和优化
微调原理
通过引入额外参数实现微调
对原模型参数进行低秩转换,降低计算复杂度
分解原始参数矩阵为较小矩阵乘积形式
主要优势
减少GPU资源需求和计算复杂度
节省显存,减少参数量
推理架构无需改变即可使用训练好的权重
应用场景
大规模预训练模型的适应和优化
适合任何通过W ∈ R^m×n参数化的线性操作
实施步骤
冻结预训练模型的权重
在每个Transformer块中注入可训练层(秩-分解矩阵)
与其他技术的比较
相比SFT、P-tuning v2等,LoRA通过低秩分解减少参数量,节省成本且效果接近全模型微调
资讯来源:Metaso.cn

8 个月前
LoRA(Low-Rank Adaptation)是一种对大模型进行“轻量级微调”的技术。

1 年前
BERT(Bidirectional Encoder Representations from Transformers)是由Google于2018年发布的一种预训练语言模型,基于Transformer架构,用于自然语言处理(NLP)任务。它的双向(Bidirectional)上下文理解能力使其在文本理解、问答系统、文本分类等任务中表现卓越。 BERT的核心特点 1. 双向上下文理解 传统语言模型(如GPT)通常是单向的(从左到右或从右到左)。 BERT采用Masked Language Model(MLM,掩码语言模型),即在训练过程中随机遮挡部分词语,并让模型根据上下文预测这些被遮挡的词,从而实现双向理解。 2. 预训练+微调(Pre-training & Fine-tuning) 预训练(Pre-training):在海量无标注文本数据(如维基百科、BooksCorpus)上进行训练,使BERT学会通用的语言知识。 微调(Fine-tuning):针对具体任务(如情感分析、问答系统、命名实体识别)进行轻量级训练,只需少量数据,即可获得良好效果。 3. 基于Transformer架构 BERT使用多层Transformer编码器,通过自注意力(Self-Attention)机制高效建模文本中的远程依赖关系。 Transformer结构相比RNN和LSTM,更适合并行计算,处理长文本能力更强。 BERT的两大核心任务 Masked Language Model(MLM,掩码语言模型) 在训练时,随机遮挡输入文本中的15%单词,让模型根据上下文预测这些词。 这种方法使BERT学习到更深层次的语言表示能力。 Next Sentence Prediction(NSP,下一句预测) 让模型判断两个句子是否是相邻句: IsNext(相关):句子A和B是原始文本中相连的句子。 NotNext(无关):句子B是随机选择的,与A无关。 这一任务有助于提高BERT在问答、阅读理解等任务中的能力。 BERT的不同版本 BERT-Base:12层Transformer(L=12)、隐藏层768维(H=768)、12个自注意力头(A=12),总参数110M。 BERT-Large:24层Transformer(L=24)、隐藏层1024维(H=1024)、16个自注意力头(A=16),总参数340M。 DistilBERT:更小更快的BERT变体,参数量约为BERT的一半,但性能接近。 RoBERTa:改进版BERT,去除了NSP任务,并采用更大数据量进行训练,提高了性能。 BERT的应用 BERT可以应用于多种NLP任务,包括: 文本分类(如垃圾邮件检测、情感分析) 命名实体识别(NER)(如人名、地名、组织识别) 阅读理解(QA)(如SQuAD问答) 文本摘要 机器翻译 搜索引擎优化(SEO)(Google已将BERT用于搜索算法) BERT的影响 推动NLP进入预训练时代:BERT的成功引发了NLP领域的“预训练+微调”范式(如GPT、T5、XLNet等)。 提升搜索引擎性能:Google 在搜索引擎中使用BERT,提高查询理解能力。 加速AI技术发展:BERT的开源推动了自然语言处理技术在学术界和工业界的广泛应用。 总结 BERT是Transformer架构的双向预训练模型,通过MLM和NSP任务学习通用语言知识,在NLP领域取得巨大突破。它的成功奠定了现代大模型预训练+微调的范式,被广泛用于搜索、问答、文本分类等任务。

1 年前
模型微调(Fine-tuning)与模型蒸馏(Knowledge Distillation)的比较 1. 定义与核心思想 模型微调 在预训练模型的基础上,通过目标任务的数据调整模型参数(通常仅调整部分层或全网络),使其适应新任务。例如,将ImageNet预训练的ResNet用于医学图像分类时,微调全连接层。 模型蒸馏 将大型教师模型(Teacher)的知识迁移到更小的学生模型(Student),使学生模仿教师的输出或中间特征。核心是通过软化输出(如带温度的Softmax)或特征对齐传递知识,实现模型压缩或性能提升。 2. 共同点 迁移学习:均利用已有模型的知识,避免从头训练。 依赖预训练模型:微调依赖预训练权重初始化,蒸馏依赖教师模型的输出作为监督信号。 提升目标性能:两者均旨在提升模型在目标任务上的表现。 3. 核心差异 -- 4. 优缺点对比 模型微调 ✅ 优点: 简单直接,快速提升目标任务性能 保留预训练模型的表征能力 ❌ 缺点: 模型大小与计算成本不变 小数据任务易过拟合 模型蒸馏 ✅ 优点: 生成轻量级模型,降低推理成本 软标签提供类别间相似性信息 ❌ 缺点: 依赖高质量教师模型 知识迁移设计复杂 5. 应用场景 模型微调: 目标任务与预训练任务相似(如不同领域的图像分类) 数据量中等,需快速适配新任务 模型蒸馏: 资源受限的部署场景(移动端、边缘设备) 利用教师模型提升小模型性能 6. 协同使用 微调教师模型:在目标任务上微调大型模型(如BERT) 蒸馏到学生模型:将知识迁移到轻量学生模型(如TinyBERT) ? 兼顾性能与效率,适用于工业级部署 7. 总结 选择微调:保持原结构 + 数据充足 选择蒸馏:压缩模型 + 降低计算成本 联合使用:先微调教师,再蒸馏学生

1 年前
在大模型(如深度学习模型)中,微调(Fine-Tuning)是指在预训练模型的基础上,对模型进行进一步的训练,以适应特定任务或数据集的需求。

8 天前
西门子Xcelerator开放式数字商业平台作为正式发布生态合作伙伴"繁星计划",旨在发挥平台网络效应,与生态伙伴共享知识与技术资源,共创面向客户的解决方案,共赢数字化与低碳化新机遇。
14 天前
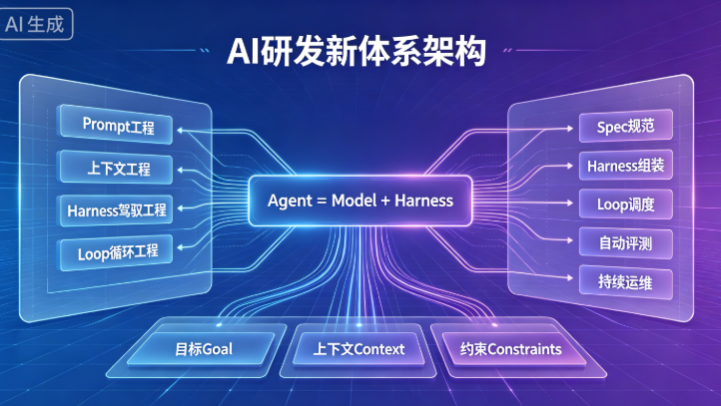
AI 研发已从单点 Prompt 优化迭代至Harness 工程底座 + Loop 自治闭环 + SDD 标准化规范的三位一体体系,通过重构人机协作模式,解决大模型落地不稳定、难规模化的痛点,实现企业级 AI 从原型试用走向工程化、自动化、体系化落地。

18 天前
WorkBuddy有望拿下国内独立桌面自动化办公智能体细分第一。但受企业协同生态、移动端能力等短板限制,无法成为全域企业及全球办公AI赛道第一名,将与钉钉悟空、WPS AI形成差异化竞争格局。

26 天前
OpenClaw工具与生态完整生命周期判断 本文尝试分短期、中期、长期三段,结合项目现状、风险、护城河客观测算OpenClaw这款智能体工具或者相似工具的发展趋势。 一、短期生命力(1~3年,2026–2029):完全安全、高速增长,是黄金运营窗口期 支撑理由 赛道刚需独一无二,差异化壁垒极强 OpenClaw是极少数本地系统级执行、模型无关、纯自托管的终端Agent运行框架,定位“能操作电脑文件、软件、桌面的AI助手”,区别于LangGraph/CrewAI这类后端开发框架、AutoGPT纯实验型智能体。普通办公、个人自动化、小微企业没有替代同类成熟开源工具,C端+中小企业需求持续释放。 社区与生态飞轮已经跑通 GitHub 30万+星标、近千名全球持续贡献者,日均数百条PR/Issue迭代,更新频率行业第一;创始人Peter全职维护,大厂(英伟达、Kimi、MiniMax)主动适配接入; ClawHub官方技能仓库沉淀数千标准化Skill,国内衍生生态(xia345、各类中文技能站、私有化二次改版)持续扩容,形成标准锁定; MIT宽松开源协议,允许企业二次改造、搭建托管服务,大量服务商入局完善配套生态(部署、安全加固、私有化定制)。 行业周期红利:本地终端Agent处于普及早期 2026被行业定义为桌面Agent落地元年,云端大模型成本持续下行、本地Ollama离线模型普及,完美匹配OpenClaw“本地优先”架构;未来3年,个人自动化、企业内网办公自动化需求只会扩张。 短期仅有的可控风险 Token调用成本偏高、频繁更新易出现版本兼容bug、本地高权限带来安全隐患; 以上问题官方正在持续迭代修复,企业级备份、权限沙箱、日志审计功能已逐步补齐,属于可优化痛点,不会动摇存续根基。 结论:未来1–3年是生态最繁荣、流量最大、变现最顺畅的阶段。 二、中期生命力(3~7年,2029–2033):稳定存续,但竞争加剧、增速放缓 存续核心逻辑 标准化生态具备长期锁定效应 SKILL.md、ClawHub统一技能规范、openclaw CLI命令行已经形成行业事实标准。就算出现竞品,开发者、存量数万套技能、企业定制项目迁移成本极高,生态不会短时间崩塌,会维持稳定使用人群。 分层商业模式支撑项目持续维护 原生项目开源免费,但周边商业化闭环成型:企业私有化部署服务、安全审计、托管云服务、垂直行业技能付费、模型渠道分销,持续产生现金流反哺社区开发,不会出现“没人维护停更”的局面。 使用人群分层留存 C端极客、办公自动化爱好者会长期使用; 中小企业内网自动化、数据处理场景高度依赖本地执行Agent,大厂SaaS Agent无法满足内网隐私需求; 开发者持续基于OpenClaw做二次分支、私有化改版,衍生生态会持续分流、延续整个“龙虾生态”的热度。 中期衰减变量(会降低增速,但不会淘汰项目) 微软、苹果、国产操作系统推出原生系统级AI助手,抢占普通小白用户; 新轻量化终端Agent开源框架分流开发者; 各国监管对本地高权限AI自动化工具出台更严格合规要求,提高企业落地门槛; 结论:3–7年不会消亡,但行业从爆发期进入存量竞争,流量红利收窄,平台需要深耕私有化、企业定制、垂直细分赛道才能持续盈利。 三、长期生命力(7年以上,2033之后):分两种极端走向 走向1:长期持续存活(概率60%),变成基础设施级工具 如果行业发展符合以下趋势,OpenClaw会像现在的Python、Git一样长期存续: 终端自主Agent成为电脑标配生产力工具,本地执行、离线隐私是永久刚需; OpenClaw持续完成企业级、合规化改造,成为政企内网自动化标准选型; 社区形成基金会/商业公司承接维护,摆脱单一创始人依赖,实现长久开源运营。 走向2:逐步边缘化、被新一代架构替代(概率40%) 触发条件: 操作系统底层内置标准化Agent执行层,统一API,第三方独立运行框架失去生存空间; 多模态、具身智能技术迭代,全新架构完全替代“技能+本地脚本执行”模式; 全球监管全面限制本地高权限自主AI工具,商用落地基本锁死,仅小众极客圈子留存。 即便被边缘化,存量存量技能、配套站点、私有部署项目仍会维持5–10年长尾生命周期,不会瞬间彻底消失。 四、关键风险:会大幅缩短生命周期的致命隐患 安全重大事故 若出现大规模Skill供应链投毒、批量本地数据泄露事件,企业端市场会快速萎缩,仅保留个人玩家生态;官方正在完善自动病毒扫描、技能审核机制,风险持续降低。 创始人断更、无承接主体 当前项目由Peter单人主导,若后续精力转移、无商业公司接手维护,迭代速度断崖式下滑,竞争力快速落后竞品;目前已有多家AI服务商、模型厂商深度合作,存在接手预期。 算力成本长期居高不下 如果大模型API按量价格无法大幅下降,普通用户长期使用成本过高,会劝退大众用户,仅留存企业付费群体。 国内政策监管收紧 国内针对本地自主自动化工具出台限制,国内衍生生态、配套导航平台流量大幅下滑,但海外生态不受影响。 五、综合最终总结 0–3年(黄金期):放心投入建站、填充内容、运营变现,生态高速扩张,流量红利充足; 3–7年(平稳期):生态稳定存在,竞争变多,需要走差异化(私有化、离线、海外双语)路线维持竞争力; 7年以上(分化期):要么成为长期基础设施永续存在,要么逐步小众长尾,即便衰退也有数年缓冲时间; 整体安全底线:至少拥有5年以上稳定商业运营周期,足够覆盖站点开发、回本、盈利完整周期;中长期只要避开通用综合赛道,主打本地离线私有化细分,生命周期会进一步拉长。










