
近年来,大型语言模型 (LLM) 的功能改变了自然语言的处理和理解,取得了显著的里程碑。尽管取得了这些进步,但 LLM 在交互式环境中仍面临重大挑战,尤其是在需要多步推理的任务(如网络导航)中。目前依赖于静态语言数据集的训练方法在使这些模型能够进行动态现实世界的交互方面存在不足。
进入 Agent Q,这是 Agent 的一个重要里程碑,它结合了搜索、自我批评和强化学习,以创建可以计划和自我修复的最先进的自主 Web 代理。我们的突破性方法通过引入一种新的学习和推理框架来解决以前LLM训练技术的局限性,以实现自主网络导航。
当前方法的问题
目前的方法,例如对精心策划的专家演示进行监督微调,由于复合错误和有限的勘探数据,往往无法完成代理多步骤任务。这些方法产生的策略次优,特别是在需要复杂决策和适应性学习的动态环境中。
Agent Q Research:解释
Agent Q 通过将引导蒙特卡洛树搜索 (MCTS) 和 AI 自我批评与迭代微调相结合进行创新,利用强化学习进行人类反馈 (RLFH) 方法,如直接偏好优化 (DPO) 算法。这种方法使LLM智能体能够从成功和不成功的轨迹中学习,从而增强了他们在多步推理任务中的泛化能力。
Agent Q 的关键组件:
使用 MCTS 进行引导搜索:这种技术通过探索不同的操作和网页来自主生成数据,平衡探索和利用。MCTS利用高采样温度和多样化的提示扩大了动作空间,确保了多样化和最优的轨迹收集。
人工智能自我批评:在每一步,基于人工智能的自我批评都会提供有价值的反馈,从而完善代理人的决策过程。这种阶梯级反馈对于长期任务至关重要,因为在长期任务中,稀疏的信号往往会导致学习困难。
直接偏好优化:DPO 算法通过从 MCTS 生成的数据构建偏好对来微调模型。这种偏离策略的训练方法使模型能够有效地从聚合数据集中学习,包括在搜索过程中探索的次优分支,从而提高复杂环境中的成功率。
真实世界验证
在 Open Table 上的真实预订实验中,MultiOn 的代理将 LLaMa-3 模型的零样本性能从 18.6% 的成功率大幅提高到 81.7%,仅在一天的自主数据收集后就提高了 340%,在线搜索后进一步提高到 95.4%。这些结果凸显了我们的方法在自主网络代理改进方面的效率和能力。
MultiOn 的 Agent Q 为自主 Web 代理设定了一个新的重要里程碑,它结合了先进的搜索技术、AI 自我批评和强化学习来克服当前的限制,代表了自主代理能力的重大飞跃。随着我们不断完善这些方法并解决相关挑战,越来越接近我们产品的全面发布,现实世界中智能自主 Web 代理的未来看起来很有希望。
14 天前
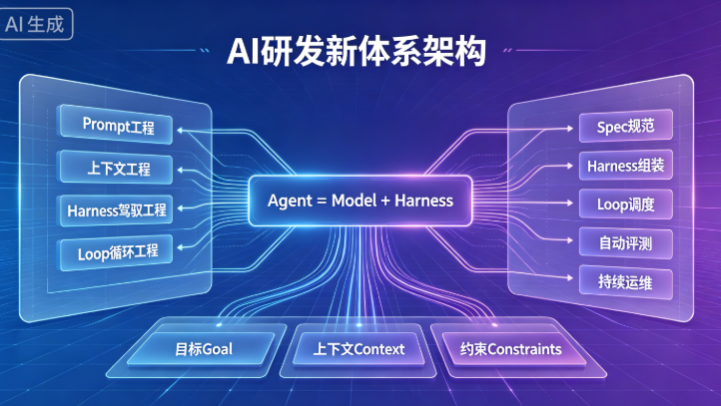
AI 研发已从单点 Prompt 优化迭代至Harness 工程底座 + Loop 自治闭环 + SDD 标准化规范的三位一体体系,通过重构人机协作模式,解决大模型落地不稳定、难规模化的痛点,实现企业级 AI 从原型试用走向工程化、自动化、体系化落地。

19 天前
WorkBuddy有望拿下国内独立桌面自动化办公智能体细分第一。但受企业协同生态、移动端能力等短板限制,无法成为全域企业及全球办公AI赛道第一名,将与钉钉悟空、WPS AI形成差异化竞争格局。

26 天前
OpenClaw工具与生态完整生命周期判断 本文尝试分短期、中期、长期三段,结合项目现状、风险、护城河客观测算OpenClaw这款智能体工具或者相似工具的发展趋势。 一、短期生命力(1~3年,2026–2029):完全安全、高速增长,是黄金运营窗口期 支撑理由 赛道刚需独一无二,差异化壁垒极强 OpenClaw是极少数本地系统级执行、模型无关、纯自托管的终端Agent运行框架,定位“能操作电脑文件、软件、桌面的AI助手”,区别于LangGraph/CrewAI这类后端开发框架、AutoGPT纯实验型智能体。普通办公、个人自动化、小微企业没有替代同类成熟开源工具,C端+中小企业需求持续释放。 社区与生态飞轮已经跑通 GitHub 30万+星标、近千名全球持续贡献者,日均数百条PR/Issue迭代,更新频率行业第一;创始人Peter全职维护,大厂(英伟达、Kimi、MiniMax)主动适配接入; ClawHub官方技能仓库沉淀数千标准化Skill,国内衍生生态(xia345、各类中文技能站、私有化二次改版)持续扩容,形成标准锁定; MIT宽松开源协议,允许企业二次改造、搭建托管服务,大量服务商入局完善配套生态(部署、安全加固、私有化定制)。 行业周期红利:本地终端Agent处于普及早期 2026被行业定义为桌面Agent落地元年,云端大模型成本持续下行、本地Ollama离线模型普及,完美匹配OpenClaw“本地优先”架构;未来3年,个人自动化、企业内网办公自动化需求只会扩张。 短期仅有的可控风险 Token调用成本偏高、频繁更新易出现版本兼容bug、本地高权限带来安全隐患; 以上问题官方正在持续迭代修复,企业级备份、权限沙箱、日志审计功能已逐步补齐,属于可优化痛点,不会动摇存续根基。 结论:未来1–3年是生态最繁荣、流量最大、变现最顺畅的阶段。 二、中期生命力(3~7年,2029–2033):稳定存续,但竞争加剧、增速放缓 存续核心逻辑 标准化生态具备长期锁定效应 SKILL.md、ClawHub统一技能规范、openclaw CLI命令行已经形成行业事实标准。就算出现竞品,开发者、存量数万套技能、企业定制项目迁移成本极高,生态不会短时间崩塌,会维持稳定使用人群。 分层商业模式支撑项目持续维护 原生项目开源免费,但周边商业化闭环成型:企业私有化部署服务、安全审计、托管云服务、垂直行业技能付费、模型渠道分销,持续产生现金流反哺社区开发,不会出现“没人维护停更”的局面。 使用人群分层留存 C端极客、办公自动化爱好者会长期使用; 中小企业内网自动化、数据处理场景高度依赖本地执行Agent,大厂SaaS Agent无法满足内网隐私需求; 开发者持续基于OpenClaw做二次分支、私有化改版,衍生生态会持续分流、延续整个“龙虾生态”的热度。 中期衰减变量(会降低增速,但不会淘汰项目) 微软、苹果、国产操作系统推出原生系统级AI助手,抢占普通小白用户; 新轻量化终端Agent开源框架分流开发者; 各国监管对本地高权限AI自动化工具出台更严格合规要求,提高企业落地门槛; 结论:3–7年不会消亡,但行业从爆发期进入存量竞争,流量红利收窄,平台需要深耕私有化、企业定制、垂直细分赛道才能持续盈利。 三、长期生命力(7年以上,2033之后):分两种极端走向 走向1:长期持续存活(概率60%),变成基础设施级工具 如果行业发展符合以下趋势,OpenClaw会像现在的Python、Git一样长期存续: 终端自主Agent成为电脑标配生产力工具,本地执行、离线隐私是永久刚需; OpenClaw持续完成企业级、合规化改造,成为政企内网自动化标准选型; 社区形成基金会/商业公司承接维护,摆脱单一创始人依赖,实现长久开源运营。 走向2:逐步边缘化、被新一代架构替代(概率40%) 触发条件: 操作系统底层内置标准化Agent执行层,统一API,第三方独立运行框架失去生存空间; 多模态、具身智能技术迭代,全新架构完全替代“技能+本地脚本执行”模式; 全球监管全面限制本地高权限自主AI工具,商用落地基本锁死,仅小众极客圈子留存。 即便被边缘化,存量存量技能、配套站点、私有部署项目仍会维持5–10年长尾生命周期,不会瞬间彻底消失。 四、关键风险:会大幅缩短生命周期的致命隐患 安全重大事故 若出现大规模Skill供应链投毒、批量本地数据泄露事件,企业端市场会快速萎缩,仅保留个人玩家生态;官方正在完善自动病毒扫描、技能审核机制,风险持续降低。 创始人断更、无承接主体 当前项目由Peter单人主导,若后续精力转移、无商业公司接手维护,迭代速度断崖式下滑,竞争力快速落后竞品;目前已有多家AI服务商、模型厂商深度合作,存在接手预期。 算力成本长期居高不下 如果大模型API按量价格无法大幅下降,普通用户长期使用成本过高,会劝退大众用户,仅留存企业付费群体。 国内政策监管收紧 国内针对本地自主自动化工具出台限制,国内衍生生态、配套导航平台流量大幅下滑,但海外生态不受影响。 五、综合最终总结 0–3年(黄金期):放心投入建站、填充内容、运营变现,生态高速扩张,流量红利充足; 3–7年(平稳期):生态稳定存在,竞争变多,需要走差异化(私有化、离线、海外双语)路线维持竞争力; 7年以上(分化期):要么成为长期基础设施永续存在,要么逐步小众长尾,即便衰退也有数年缓冲时间; 整体安全底线:至少拥有5年以上稳定商业运营周期,足够覆盖站点开发、回本、盈利完整周期;中长期只要避开通用综合赛道,主打本地离线私有化细分,生命周期会进一步拉长。

4 个月前
OpenClaw 本质是“开发者基础设施”,而非面向大众的 SaaS 产品。

5 个月前
用 OpenClaw 搭建一个本地 Agent 中枢(完整方案) 不是再做一个 ChatGPT,而是建立一个真正“可控、可组合、可扩展”的本地 AI Agent 中枢。 当越来越多团队开始意识到: 云端 LLM 成本不可控 数据隐私存在风险 单一 Agent 无法解决真实业务 “本地 Agent 中枢” 正在成为一个更现实的选择。 本文将完整讲清楚: ? 如何用 OpenClaw 搭建一个真正可用的本地 Agent 中枢 ? 它适合谁,不适合谁 ? 与 LangGraph / CrewAI 的核心差异 什么是「本地 Agent 中枢」? 先明确一个概念,避免误解。 ❌ 不是: 一个本地 ChatGPT 一个简单的 Prompt 管理器 ✅ 而是: 一个能够统一管理多个 Agent、模型、工具和任务流程的本地系统 一个合格的本地 Agent 中枢,至少要解决 5 件事: 多 Agent 协作(不是单轮对话) 任务调度与状态管理 模型可替换(本地 / API) 工具调用(搜索、代码、文件等) 可长期运行、可追溯 OpenClaw 的定位,正是这个“中枢层”。 为什么选择 OpenClaw? 在进入部署前,必须先回答一个现实问题: 为什么不是 LangGraph / CrewAI / AutoGen? 简要结论(非常重要) 框架 更适合 LangGraph 开发者写 Agent 流程 CrewAI 小规模角色协作 AutoGen 对话驱动实验 OpenClaw 长期运行的 Agent 中枢 OpenClaw 的核心优势 1️⃣ 架构清晰,不是“脚本拼装” 有明确的 Agent 管理层 有任务执行与状态机制 不是写完一次就丢的 Demo 2️⃣ 原生支持多模型策略 本地模型 云 API fallback / 优先级策略 3️⃣ 更接近“生产环境思维” 可持续运行 可复用 Agent 可演进 如果你的目标是: “做一个长期使用的 AI 中枢,而不是一段实验代码” 那 OpenClaw 是目前更合理的选择之一。 整体架构:OpenClaw 本地 Agent 中枢怎么搭? 这是一个最小可用但可扩展的架构方案。 ? 架构拆解 ┌─────────────────────────┐ │ 用户 / 系统 │ └──────────┬──────────────┘ │ ┌──────────▼──────────┐ │ OpenClaw 中枢层 │ │ - Agent Registry │ │ - Task Orchestrator│ │ - Memory / State │ └──────────┬──────────┘ │ ┌─────────▼─────────┐ │ Agent 集群 │ │ - Research Agent │ │ - Coding Agent │ │ - Planning Agent │ │ - Tool Agent │ └─────────┬─────────┘ │ ┌─────────▼─────────┐ │ 模型 & 工具层 │ │ - 本地 LLM │ │ - API LLM │ │ - Search / FS / DB │ └───────────────────┘ 部署准备(实战级) 1️⃣ 基础环境 推荐环境(已验证): Linux / WSL / macOS Docker + Docker Compose Python 3.10+ 2️⃣ 模型选择建议(非常现实) 场景 推荐 本地推理 Qwen / LLaMA 稳定输出 GPT / Claude API 混合方案 本地 + API fallback ? 关键不是模型多,而是“可切换” 核心步骤:搭建 OpenClaw 本地 Agent 中枢 Step 1:部署 OpenClaw 核心 git clone https://github.com/xxx/openclaw cd openclaw docker compose up -d 启动后,你将拥有: Agent 管理入口 任务调度服务 统一配置中心 Step 2:定义你的第一个 Agent 一个 Agent ≠ 一个 Prompt 而是一个职责明确的“角色” 示例: agent: name: research_agent role: 信息调研 model: local_llm tools: - web_search - file_reader 建议起步 Agent: Research Agent(信息收集) Planner Agent(任务拆解) Executor Agent(执行) Step 3:建立 Agent 协作流程 例如一个典型任务: “调研某行业 → 输出分析 → 给出建议” 流程是: Planner 拆解任务 Research Agent 收集信息 Executor Agent 输出结果 中枢保存状态与结果 ? 这一步,才是“中枢”的价值所在 一个真实可用的示例场景 ? 场景:AI 工具评估中枢 你可以搭一个 Agent 中枢来做: 自动收集 AI 工具信息 对比功能 / 定价 输出结构化报告 长期更新 这类系统: 人工成本极高 用 Agent 非常合适 总结:什么时候该用 OpenClaw? 当你意识到:AI 不再是“一次性回答”,而是“持续协作的系统” 那你就已经走在 OpenClaw 这条路上了。 OpenClaw 不是让你“更快用 AI”,而是让你“真正拥有 AI 能力”。

5 个月前
Asking User Question Tool(AI智能体版) 这是AI智能体必备的交互式工具,让Agent在执行任务时主动向用户提问、澄清需求、收集信息,避免瞎猜、减少返工、提升准确率。 一、核心定位 本质:Agent的“人在回路”交互接口,让AI在模糊/信息不足时暂停执行,向用户要明确输入。 作用:把“模糊指令→AI瞎做→反复修改”变成“AI提问→用户明确→一次做对”。 常见名称: AskUserQuestion 、 AskUserQuestionTool 、 ask_user_question 。 二、核心工作流(极简) 1. Agent判断信息不足:发现需求模糊、缺少参数、需要决策 2. 调用工具生成结构化问题:单选/多选+自定义输入+说明 3. 用户作答:在聊天/弹窗/终端选择或输入 4. Agent接收答案:解析结构化结果,补全上下文 5. 继续执行任务:基于完整信息推进,不再猜 三、关键能力(标配) 结构化提问:标题+问题+2–4个选项+单选/多选+ Other 自定义输入 上下文澄清:自动追问,直到需求完全明确 结构化返回:输出JSON,方便前端渲染(按钮/表单/弹窗) 人在回路:强制用户确认,避免AI自主决策风险 多轮交互:可连续提问,形成“需求访谈”流程 四、主流实现(你会遇到的版本) Claude Code(Anthropic) 原生内置,最成熟 支持多轮、单选/多选、自定义输入 常用于代码生成、需求梳理 Qwen-Agent(通义千问) 开源工具: qwen_agent/tools/ask_user_question.py 支持参数: question / options / explanations / multiSelect / allowFreeform Spring AI AskUserQuestionTool ,Java生态 模型无关,可对接GPT/Claude/Gemini OpenClaw / EasyClaw 集成到本地智能体,用于任务执行前确认 本地运行,隐私优先 五、典型使用场景(高频) 需求澄清:“做一个登录页”→AI问:技术栈?风格?是否第三方登录? 偏好收集:“写报告”→AI问:正式/ casual?长度?受众? 决策点确认:“部署服务”→AI问:云厂商?实例规格?环境? 复杂任务拆解:多轮提问,把模糊需求变成可执行步骤 六、与普通聊天的区别 普通聊天:用户主动说,AI被动答;信息靠用户自己补全 AskUserQuestion:AI主动问、结构化问、按任务节点问;用户只需点选/填空,效率高、歧义少 七、为什么要用(价值) 减少返工:一次做对,节省时间与Token 提升准确率:AI不瞎猜,结果更贴合需求 降低门槛:用户不用写长Prompt,点选即可 安全可控:关键决策必须用户确认,避免误操作 八、一句话总结 Asking User Question Tool = AI智能体的“需求访谈官”,让Agent从“猜着做”变成“问清楚再做”,是构建可靠、实用AI助手的核心工具。

5 个月前
部署本地 OpenClaw 主要有两种主流且资料详尽的方式,你可以根据自己的技术背景和需求来选择。 我把这两种方式的流程整理成了一个概览表格,方便你快速对比和决策: 特性 方案一:Docker 部署(推荐新手) 方案二:Node.js 源码部署(适合开发者) 核心依赖 Docker, Docker Compose, Git Node.js (≥22), npm, Git 优点 环境隔离,部署和卸载干净,失败率低,适合快速体验 配置灵活,方便二次开发和调试,可直接运行最新源码 缺点 需要了解基本的 Docker 命令 对系统环境要求较高,可能遇到依赖冲突 适用人群 希望快速、稳定运行OpenClaw的用户 开发者、希望修改源码或深度定制OpenClaw的用户 方案一:使用 Docker 部署(推荐) 这种方法将 OpenClaw 运行在容器中,与你的系统环境隔离,最为稳妥。 第1步:准备工作与环境检查 在开始之前,请确保你的电脑满足最低要求:CPU ≥ 2核,内存 ≥ 4GB,磁盘空间 ≥ 20GB 。 第2步:安装通用依赖 你需要安装 Docker、Git 等工具。以下是 Linux (Ubuntu/Debian) 的示例命令,Windows 用户请手动下载安装 Docker Desktop 和 Git 。 # 1. 安装 Docker (使用阿里云镜像加速) curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun # 2. 启动 Docker 并设置开机自启 sudo systemctl start docker sudo systemctl enable docker # 3. 验证 Docker 安装 docker --version && docker compose version # 4. 安装 Git sudo apt update && sudo apt install git -y git --version 第3步:获取 OpenClaw 源码与镜像 创建工作目录,并拉取汉化版的源码和预构建的 Docker 镜像 。 # 1. 创建并进入部署目录 mkdir -p /opt/openclaw && cd /opt/openclaw # 2. 拉取2026版OpenClaw源码(汉化版) git clone https://github.com/openclaw-community/openclaw-zh.git . # 3. 拉取OpenClaw核心镜像(国内加速源) docker pull registry.cn-hangzhou.aliyuncs.com/openclaw/openclaw-core:2026-zh docker pull registry.cn-hangzhou.aliyuncs.com/openclaw/openclaw-web:2026-zh # 4. 验证镜像拉取结果 docker images | grep openclaw 第4步:初始化配置文件 复制配置文件模板并进行修改,填入你的 API Key 等重要信息 。 # 1. 复制默认配置文件 cp config/example.yaml config/config.yaml # 2. 编辑配置文件 (这里使用nano,你也可以用vim) nano config/config.yaml 找到文件中的对应部分,修改为以下内容。请务必将 你的阿里云百炼API-Key 替换为你自己的密钥 。 # ① 模型配置(替换为你的API-Key) models: providers: bailian: apiKey: "你的阿里云百炼API-Key" # <-- 在这里填入你的Key model: "bailian/qwen3-max-2026-01-23" # ② 服务端口配置 server: port: 18789 host: "0.0.0.0" # 监听所有网络接口,方便局域网内访问 # ③ 数据存储配置(本地路径) storage: local: path: "/opt/openclaw/data" 保存文件 (nano 中按 Ctrl+X,然后按 Y 确认,再按 Enter)。 第5步:启动 OpenClaw 服务 使用 Docker Compose 启动服务,并检查运行状态 。 # 1. 启动服务(后台运行) docker compose up -d # 2. 查看服务启动状态(所有容器应为 "Up" 状态) docker compose ps # 3. (可选)查看启动日志,确保无错误 docker compose logs -f 第6步:访问并完成初始化 打开浏览器,访问 http://127.0.0.1:18789 (如果在本机) 或 http://你的局域网IP:18789。首次访问时,页面会引导你设置管理员密码,之后就可以开始使用你的 OpenClaw 了 。 方案二:使用 Node.js 从源码部署 这种方式更贴近开发环境,适合需要定制功能的用户。 第1步:安装 Node.js 环境 OpenClaw 需要 Node.js 22 或更高版本 。推荐使用 NodeSource 仓库进行安装。 # 1. 添加 NodeSource 仓库 (以 Node.js 22 为例) curl -fsSL https://deb.nodesource.com/setup_22.x | sudo -E bash - # 2. 安装 Node.js sudo apt install -y nodejs # 3. 验证安装 node -v # 应显示 v22.x.x 或更高 npm -v # 4. (可选) 配置 npm 国内镜像加速 npm config set registry https://registry.npmmirror.com 第2步:安装 OpenClaw 官方提供了一个一键安装脚本,会自动完成全局安装 。 # macOS / Linux 系统执行 curl -fsSL https://openclaw.ai/install.sh | bash 安装脚本执行完成后,会自动进入一个名为 onboard 的交互式设置向导。如果向导中断,你可以随时通过 openclaw onboard --install-daemon 命令重新启动 。 第3步:处理可能遇到的问题 command not found 错误: 安装后如果找不到 openclaw 命令,通常是因为 npm 的全局安装目录不在系统的 PATH 环境变量中。你可以通过 npm prefix -g 找到该目录(例如 /usr/local),然后将 export PATH="$(npm prefix -g)/bin:$PATH" 添加到你的 ~/.bashrc 或 ~/.zshrc 文件中,并执行 source ~/.bashrc 使其生效 。 sharp 模块安装失败: 在某些系统上,可能会遇到图像处理库 sharp 的安装错误。可以尝试设置环境变量绕过本地编译:SHARP_IGNORE_GLOBAL_LIBVIPS=1 npm install -g openclaw@latest 。 第4步:运行 OpenClaw 完成配置后,你可以通过以下命令启动 OpenClaw 的 Gateway 核心服务 : openclaw gateway 然后,打开浏览器访问 http://127.0.0.1:18789 即可看到 Web 控制台界面 。 总的来说,对于大多数想要本地尝鲜的朋友,我强烈建议使用 Docker 方案,它足够简单且不容易把系统环境弄乱。如果你是个喜欢折腾的开发者,希望深入定制 OpenClaw 的能力,那么 Node.js 源码部署会更适合你。

5 个月前
2026年2月,维也纳这座古典音乐之都意外成为AI开源社区的焦点。继旧金山ClawCon之后,OpenClaw(中文社区昵称“小龙虾”或“龙虾”)的欧洲首场线下盛会——ClawCon Vienna顺利举办,吸引了约500名开发者、创业者、AI爱好者和非技术背景的“蟹教徒”齐聚一堂。现场能量爆棚,原定场地直接爆满,主办方紧急加开直播点,线上线下同步狂欢。这场聚会不仅是技术分享,更是“养龙虾”亚文化的一次集体高光。 Peter Steinberger:家乡英雄的“衣锦还乡” OpenClaw创始人Peter Steinberger(中文圈常称“虾爸”或“龙虾之父”)是奥地利本地人,曾就读维也纳工业大学,早年创办PSPDFKit(移动PDF解决方案公司),2021年以高价出售大部分股份后一度“退休”。2025年底,他重出江湖推出Clawdbot(后更名为OpenClaw),一个完全本地运行、开源的自主AI Agent框架,支持多模型调用、工具集成和复杂任务执行。 在维也纳大会上,Peter以“回家”姿态登台,分享了项目从车库原型到全球现象的历程。他强调OpenClaw的核心理念:让普通人也能轻松拥有强大AI能力,无需编程门槛,就能让Agent完成从酿啤酒配方生成到模拟小型公司运营的各种任务。现场开发者分享真实案例,有人用它自动化职场周报,有人构建个人知识库,还有人让它24小时监控市场情报。企业家和开发者一致认为,“Agent经济”已在悄然成型,而OpenClaw正成为这场革命的先锋。 从聊天框“逃离”:3D可视化与具身进化 大会最亮眼的Demo之一来自开发者Dominik Scholz。他基于OpenClaw打造了一个3D交互界面(使用Three.js + Electron),将Agent的推理过程从线性文本“解放”到三维空间:思考路径如星云扩散、决策节点如能量流,用户可以从“驾驶舱视角”直观观察AI内部逻辑,避免传统黑盒体验。 这一展示呼应了社区共识:未来的AI Agent不应永远困在对话框里,而应向更沉浸、更具情绪价值的形态进化。有人开玩笑说,早期的“soul.md”文件被删是为了“净化灵魂”,但也反映出大家对AI具身化、元宇宙式交互的热情探索。 史上首款“龙虾手机”亮相:25美元实现廉价具身AI 另一个重磅炸场的是开发者Marshall的ClawPhone项目。他在一台仅售25美元的廉价手机上安装OpenClaw,并授予完整硬件权限。Agent可直接调用麦克风、摄像头、短信、打印机等,实现实时TTS(语音合成)、浏览器自动化、短信预约、设备远程控制等功能。 现场演示中,ClawPhone通过打印机错误音“哔哔”反馈任务状态、WhatsApp审批流程、甚至自主预约日程。Marshall认为,这种极客玩具预示未来:每个房间、实验室或小型机器人可能都配备类似廉价“龙虾终端”——断网也能运行,极端情况下“一锤砸掉”即可关停,形成分布式、去中心化的具身AI节点。 全球“养龙虾”浪潮:从旧金山到维也纳,再到亚洲 ClawCon Vienna是OpenClaw全球化扩张的又一里程碑。上周旧金山首场ClawCon已吸引超1000人,韩国AI女友项目Clawra上线后一夜爆火。全球开发者正围绕OpenClaw构建技能市场、Prompt库、多Agent协作系统,从单一工具演变为活跃开源生态。 维也纳的狂欢证明:OpenClaw已超越技术本身,成为一种社区文化现象。“蟹教徒”“虾粮”“蜕皮进化”“龙虾大逃杀”等梗在中文圈刷屏,英文社区也同步玩梗。项目从本地运行到硬件具身、从聊天框到3D空间,正在以惊人速度进化。 结语:小龙虾的下一个蜕皮 维也纳ClawCon不是终点,而是OpenClaw“征服全世界”叙事的又一章。Peter Steinberger的回归、社区的狂热、硬件的创新,都在告诉我们:开源AI Agent的春天来了,而“小龙虾”正以最意想不到的方式,搅动整个行业。










