
蝉镜是蝉妈妈旗下的 AI 数字人短视频与直播平台,主要有以下特点和功能:


6 个月前
GTM(Go-to-Market)市场进入策略,是一个整合了产品定位、定价、渠道、销售和客户成功的系统性工程。

1 年前
我们在开发网站的时候,往往有想克隆别人网站的想法。那么在技术上怎么才能实现呢? ⚠️ 重要提示 确认目标网站的版权和合法性:如果你没有目标网站的授权,直接克隆并使用可能会侵犯版权或违反法律。 如果只是想模仿其功能或界面,建议自行开发类似的网站,而不是直接复制。 如果你拥有授权,可以使用以下方法进行克隆。 ? 方法 1:使用 HTTrack 下载整个网站 HTTrack 是一个网站克隆工具,可用于离线浏览: 下载安装 HTTrack(Windows/macOS/Linux 都支持)。 创建新项目 并输入目标网站 URL地址。 启动克隆,HTTrack 会下载 HTML、CSS、JS、图片等资源。 本地查看和编辑,然后上传到自己的服务器。 缺点: 只能克隆静态页面(HTML、CSS、JS),无法克隆后端功能(如 API、数据库、登录系统等)。 如果目标网站有反爬虫策略,可能无法完整下载。 ? 方法 2:手动分析 & 重新开发 如果你想复制网站的功能,而不仅仅是外观,建议进行以下操作: 1. 分析网站前端 使用 Chrome 开发者工具(F12) 查看 HTML 结构、CSS 样式和 JavaScript 逻辑。 使用 Postman 或浏览器 Network 面板 分析 API 接口调用方式(如果适用)。 复制或编写类似的 HTML/CSS/JS 代码,实现前端界面。 2. 分析网站后端 如果网站有 API 接口、数据库等后端功能,需要: 观察 API 调用(GET/POST 请求)以了解数据交互方式。 搭建类似的后端(Node.js、Python、PHP、Go 等),并使用数据库(MySQL、MongoDB 等)。 如果网站使用的是 OpenAI API,你可以在 申请 API Key,然后在你的项目中集成 ChatGPT 或 DALL·E 相关功能。 3. 部署你的网站 本地开发:使用 HTML + CSS + JavaScript + 后端框架(如 Flask、Express、Django)。 云端部署:选择服务器(AWS、阿里云、Vultr、腾讯云等)并部署网站。 ? 方法 3:使用 Web Scraping(仅用于数据获取) 如果你只想获取网页上的文本数据,可以使用 Python + BeautifulSoup / Selenium 进行爬取: import requests from bs4 import BeautifulSoup url = "http://openai.cha-tai.cn/" response = requests.get(url) soup = BeautifulSoup(response.text, 'html.parser') # 提取页面文本 text = soup.get_text() print(text) 注意: 如果网站有反爬虫机制,可能需要使用 Selenium 或 Scrapy 进行爬取。 只能获取静态数据,无法克隆网站的功能。 ? 结论 如果你只是想获取网站的内容,HTTrack 或 Web Scraping 可能够用。 但如果你想克隆网站的功能,建议分析前端和后端结构,并自行开发。

1 年前
AI视频生成模型的主要技术原理包括多种深度学习和机器学习技术,尤其是生成对抗网络(GANs)、变分自编码器(VAEs)和自然语言处理(NLP)。
1 年前
语言大模型(LLM)能够生成图片和视频的能力主要依赖于其多模态学习和生成技术。
1 年前
英伟达在AI和计算领域的多项创新应用与解决方案,涵盖了从数字人类构建、生成式AI集成、到药物发现模拟等多个方面。
2 年前
Meta推出了其 “分割一切AI” 的第二代——SAM2,不仅能实时处理任意长度的视频,连视频中从未见过的物体也能轻松分割追踪。

9 天前
西门子Xcelerator开放式数字商业平台作为正式发布生态合作伙伴"繁星计划",旨在发挥平台网络效应,与生态伙伴共享知识与技术资源,共创面向客户的解决方案,共赢数字化与低碳化新机遇。
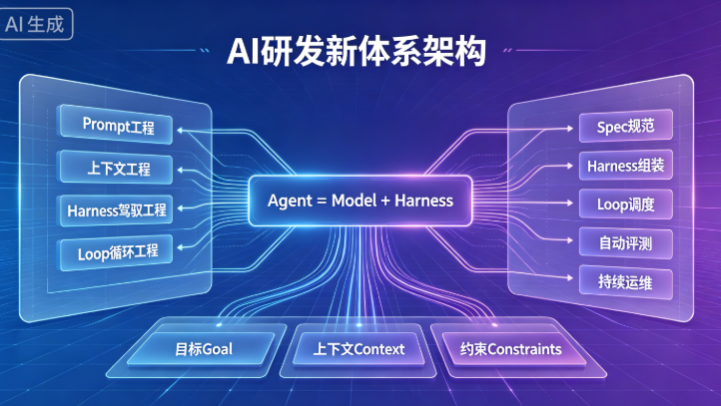
15 天前
AI 研发已从单点 Prompt 优化迭代至Harness 工程底座 + Loop 自治闭环 + SDD 标准化规范的三位一体体系,通过重构人机协作模式,解决大模型落地不稳定、难规模化的痛点,实现企业级 AI 从原型试用走向工程化、自动化、体系化落地。




















