
中国算力基础设施高质量发展行动计划
算力是集信息计算力、网络运载力、数据存储力于一体的
新型生产力,主要通过算力基础设施向社会提供服务。算力基
础设施是新型信息基础设施的重要组成部分,呈现多元泛在、
智能敏捷、安全可靠、绿色低碳等特征,对于助推产业转型升
级、赋能科技创新进步、满足人民美好生活需要和实现社会高
效能治理具有重要意义。为加强计算、网络、存储和应用协同
创新,推进算力基础设施高质量发展,充分发挥算力对数字经
济的驱动作用,制定本行动计划。
一,主要目标:
至2025 年,计算力方面,算力规模超过 300 EFLOPS,智能算力占比达到 35%,东西部算力平衡协调发展。
运载力方面,国家枢纽节点数据中心集群间基本实现不高于理论时延 1.5 倍的直连网络传输,重点应用场所光传送网(OTN)覆盖率达到 80%,骨干网、城域网全面支持 IPv6,SRv6等创新技术使用占比达到 40%。
存储力方面,存储总量超过 1800EB,先进存储容量占比达
到 30%以上,重点行业核心数据、重要数据灾备覆盖率达到
100%。
应用赋能方面,打造一批算力新业务、新模式、新业态,
工业、金融等领域算力渗透率显著提升,医疗、交通等领域应
用实现规模化复制推广,能源、教育等领域应用范围进一步扩
大。每个重点领域打造 30 个以上应用标杆。
二,重点任务
完善算力综合供给体系
优化算力设施建设布局。按照全国一体化算力网络国家
枢纽节点布局,京津冀、长三角、粤港澳大湾区、成渝等节点
面向重大区域发展战略实施需要有序建设算力设施;贵州、内
蒙古、甘肃、宁夏等节点推进数据中心集群建设同时,着力提
升算力设施利用效率,促进东西部高效互补和协同联动。加强
数据中心上架率等指标监测,整体上架率低于 50%的地区规划
新建项目应加强论证。支持我国企业“走出去”,以“一带一
路”沿线国家为重点布局海外算力设施,提升全球化服务能力。
推动算力结构多元配置。结合人工智能产业发展和业务
需求,重点在西部算力枢纽及人工智能发展基础较好地区集约
化开展智算中心建设,逐步合理提升智能算力占比。推动不同
计算架构的智能算力与通用算力协同发展,满足均衡型、计算
和存储密集型等各类业务算力需求。
促进边缘算力协同部署。加快边缘算力建设,支撑工业制造、金融交易、智能电网、云游戏等低时延业务应用,推动
“云边端”算力泛在分布、协同发展。加强行业算力建设布局,
满足工业互联网、教育、交通、医疗、金融、能源等行业应用
需求,支撑传统行业数字化转型。
推动算力标准体系建设。加快制定面向业务需求的算力
设施、IT 设备、智能运营等方面的基础共性标准,完善相关技
术要求、测试方法等,充分发挥标准对产业发展的引领和推动
作用。同步探索算力计量、感知、调度、互通、交易等方面标
准建设,支撑算网融合产业化发展。
提升算力高效运载能力
优化算力高效运载质量。探索构建布局合理、泛在连接、灵活高效的算力互联网。增强异构算力与网络的融合能力,通过网络的应用感知和资源分配机制,及时响应各类应用需求,实现计算、存储的高效利用。针对智能计算、超级计算和边缘计算等场景,开展数据处理器(DPU)、无损网络等技术升级
与试点应用,实现算力中心网络高性能传输。
强化算力接入网络能力。推动城域光传输设备向综合接
入节点和用户侧部署,加快实现大带宽、低时延的全光接入网
络广泛覆盖,城区重要算力基础设施间时延不高于 1ms。提升
边缘节点灵活高效入算能力,满足企业快速、就近、灵活、高
效联接算力需求。
提升枢纽网络传输效率。推动算力网络国家枢纽节点直
连网络骨干节点,逐步建成集群间一跳直达链路,国家枢纽节
点内重要算力基础设施间时延不高于 5ms。推动超低损光纤部
署,优化光缆路由。加快 400G/800G 高速光传输网络研发部署
和全光交叉、SRv6、网络切片、灵活以太网、光业务单元等技
术应用,实现网络传输智能高效、灵活敏捷、按需随选。
探索算力协同调度机制。推动以云服务方式整合算力资
源,充分发挥云计算资源弹性调度优势。鼓励各方探索打造多
层次算力调度架构体系,建设可满足各类创新主体开展多元异
构算力调度、应用、研发、验证的平台环境。依托国家新型互
联网交换中心、骨干直联点等设施,促进多方算力互联互通。
信息来源:gov.cn

1 年前
华为昇腾推出的Atlas 900 SuperCluster成为国产AI算力的重要突破,标志着华为在超大规模AI训练集群领域的领先地位。 1. 技术突破与性能表现 超大规模算力支持:Atlas 900 SuperCluster 采用创新的超节点架构,支持超万亿参数大模型训练,单集群可管理数十万张昇腾AI加速卡(如昇腾910B),并实现高可用性设计,包括超高速互联、高效液冷散热和瞬时爆发供电。 性能对标英伟达A100:实测数据显示,昇腾AI集群在训练Meta Llama、BloomGPT等模型时,效率可达英伟达A100的1.1倍,并在部分场景实现10倍领先于其他国产方案。 国产化算力标杆:科大讯飞等企业已采用昇腾万卡集群,训练效率达到英伟达A100的0.8~1.2倍,证明其在国产大模型训练中的竞争力。 2. 架构与生态创新 全栈自主可控:从硬件(昇腾芯片、鲲鹏CPU)、架构(达芬奇架构)、软件(MindSpore框架)到开发工具(CANN异构计算),华为构建了完整的AI计算产业链。 昇腾910B芯片升级:相比前代昇腾910,910B在FP32性能上显著提升,支持多NPU模组互联,提供更高带宽和算力密度,进一步缩小与英伟达高端GPU的差距。 生态挑战与机遇:尽管昇腾算力已对标英伟达,但CUDA生态的成熟度仍是竞争短板。华为通过开源MindSpore、适配主流框架(如PyTorch、TensorFlow)及开发者扶持计划(如15亿美元生态投入)加速生态建设。 华为Atlas 900 SuperCluster的推出,不仅提升了国产AI集群的竞争力,也为全球AI算力格局注入了新变量。随着生态完善,昇腾有望在AI训练与推理市场占据更关键地位。 (根据资讯整理)

1 年前
从传统认知来看,算力、算法和数据被认为是人工智能的核心三大要素。当大模型出现后,大模型在当前人工智能发展中占据着极其重要的地位。 大模型与算法的关系:从属而非取代。传统算法的定位:算法本质是解决问题的步骤规则,如SVM、随机森林等,是AI的底层方法论。 大模型的本质:大模型是算法的一种高级形态,依托深度学习(尤其是Transformer架构)实现,其核心仍是算法逻辑的演进。例如,GPT的生成能力源于自注意力机制(算法创新),而非脱离算法的新存在。 大模型为何需要独立强调? 尽管大模型属于算法范畴,但其独特性使其具备基础设施属性: 平台化能力:如GPT-4可作为基础平台,支撑多样下游任务(写代码、客服、科研),类似操作系统。 资源门槛:训练大模型需超算集群和千亿级数据,远超传统算法,成为独立的技术-资源综合体。 生态影响:催生模型即服务(MaaS),改变行业分工(如企业无需自研模型,调用API即可)。 AI的核心能力确实高度依赖于数据、算力和大模型,但这三者并非全部。它们是推动现代AI发展的基础设施,但真正的核心能力还需结合其他关键要素,以下分层次解析: 1. 数据、算力、大模型的角色 数据:AI的“燃料”,尤其是监督学习和自监督学习依赖海量标注或无标注数据(如GPT-4训练用了数万亿词元)。 算力:硬件(如GPU/TPU集群)支撑大规模训练和推理,例如训练GPT-4需数万块GPU和数月时间。 大模型:通过参数量的增加(如千亿级参数)实现更强的泛化和多任务能力,如Transformer架构的涌现能力。 2. 被忽视的核心要素 算法创新: 数据与算力的价值需通过算法释放。例如,Transformer(2017)相比RNN的突破、扩散模型对生成任务的改进,均源于算法设计。 小样本学习(Few-shot Learning)、强化学习的策略优化(如PPO算法)证明:算法效率可弥补数据或算力的不足。 工程能力: 分布式训练框架(如Megatron、DeepSpeed)、模型压缩(量化、蒸馏)等技术,决定大模型能否实际落地。 领域知识: 医疗AI依赖专家标注和病理学知识,自动驾驶需融合传感器物理模型,说明垂直场景的壁垒远超大模型本身。 3. 未来趋势:超越“大力出奇迹” 高效训练与推理: 低功耗芯片(如神经拟态计算)、MoE架构(如Mixtral 8x7B)正降低对算力的依赖。 数据质量 vs 数量: 合成数据(如NVIDIA Omniverse)、数据清洗技术逐步减少对纯数据量的需求。 可解释性与安全: 模型对齐(Alignment)、因果推理等能力将成为下一代AI的竞争焦点(如Anthropic的Claude 3)。 4. 总结:AI的核心能力是“系统级创新” 短期:数据、算力、大模型是入场券; 长期:算法设计、跨学科融合(如神经科学)、工程优化、伦理治理等系统性能力才是关键。 类比:如同火箭需要燃料(数据)、引擎(算力)、设计(模型),但真正的突破来自材料科学(算法)与控制系统(工程)。 未来AI的竞争将不仅是资源的堆砌,而是如何用更少的资源解决更复杂的问题,这需要多维度的创新能力。

1 年前
中美 AI 竞争已进入白热化阶段,技术差距的缩小、数据瓶颈的突破以及地缘政治的影响将成为未来 AI 发展的关键因素。

1 年前
海光处理器属于GPGPU架构,通用且场景支撑能力强,这是国内唯一具备全精度浮点数据计算能力的厂商。

2 年前
算力是集信息计算力、网络运载力、数据存储力于一体的新型生产力,主要通过算力基础设施向社会各个行业提供计算能力服务。

8 天前
西门子Xcelerator开放式数字商业平台作为正式发布生态合作伙伴"繁星计划",旨在发挥平台网络效应,与生态伙伴共享知识与技术资源,共创面向客户的解决方案,共赢数字化与低碳化新机遇。
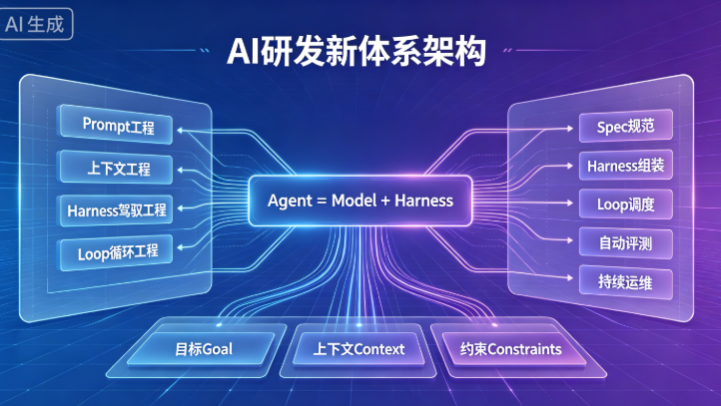
14 天前
AI 研发已从单点 Prompt 优化迭代至Harness 工程底座 + Loop 自治闭环 + SDD 标准化规范的三位一体体系,通过重构人机协作模式,解决大模型落地不稳定、难规模化的痛点,实现企业级 AI 从原型试用走向工程化、自动化、体系化落地。

18 天前
WorkBuddy有望拿下国内独立桌面自动化办公智能体细分第一。但受企业协同生态、移动端能力等短板限制,无法成为全域企业及全球办公AI赛道第一名,将与钉钉悟空、WPS AI形成差异化竞争格局。










